fix: 增加日记记录
This commit is contained in:
715
language/Python区块链/Python与数据库.md
Normal file
715
language/Python区块链/Python与数据库.md
Normal file
@@ -0,0 +1,715 @@
|
||||
# 第3章 Python与数据库
|
||||
Python程序一般是运行在内存中,当程序停止时运行的结果也就随之消失了。想要将运行的结果保存起来,如果数据量比较少,可以借助此前提到的IO操作写入到文本文件中或Excel中,但是如果数据量比较大,还有运行时期望对数据进行筛选操作,就需要用到数据库。
|
||||
|
||||
Python对各种类型数据库的读写都提供了完善的支持,一般对数据库的增、删、改、查操作在Python中实现起来也并不复杂,下面我们简单介绍一下使用Python读写关系型数据库Mysql和非关系型数据库MongoDB及Redis的方法。
|
||||
## 3.1 Python与关系型数据库
|
||||
关系型数据库,顾名思义,是指以关系模型来组织数据的数据库,数据库中一般以行和列的形式存储数据,以便于用户理解。一系列的行和列组成了表,而多个表共同组成了数据库。用户查询数据时通过指定表内列的条件,获取到所有符合条件的行数据。
|
||||
|
||||
关系模型可以理解为二维的表格模型,关系型数据库就是由多个二维表格和表格间的关系组成。一般常用的关系型数据库有MySql、Oracle、Sqlite和PostgreSql等。
|
||||
|
||||
下面我们以Mysql为例,学习如何使用Python操作关系型数据库。
|
||||
### 3.1.1 Python与MySQL开发环境准备
|
||||
* 下载MySql
|
||||
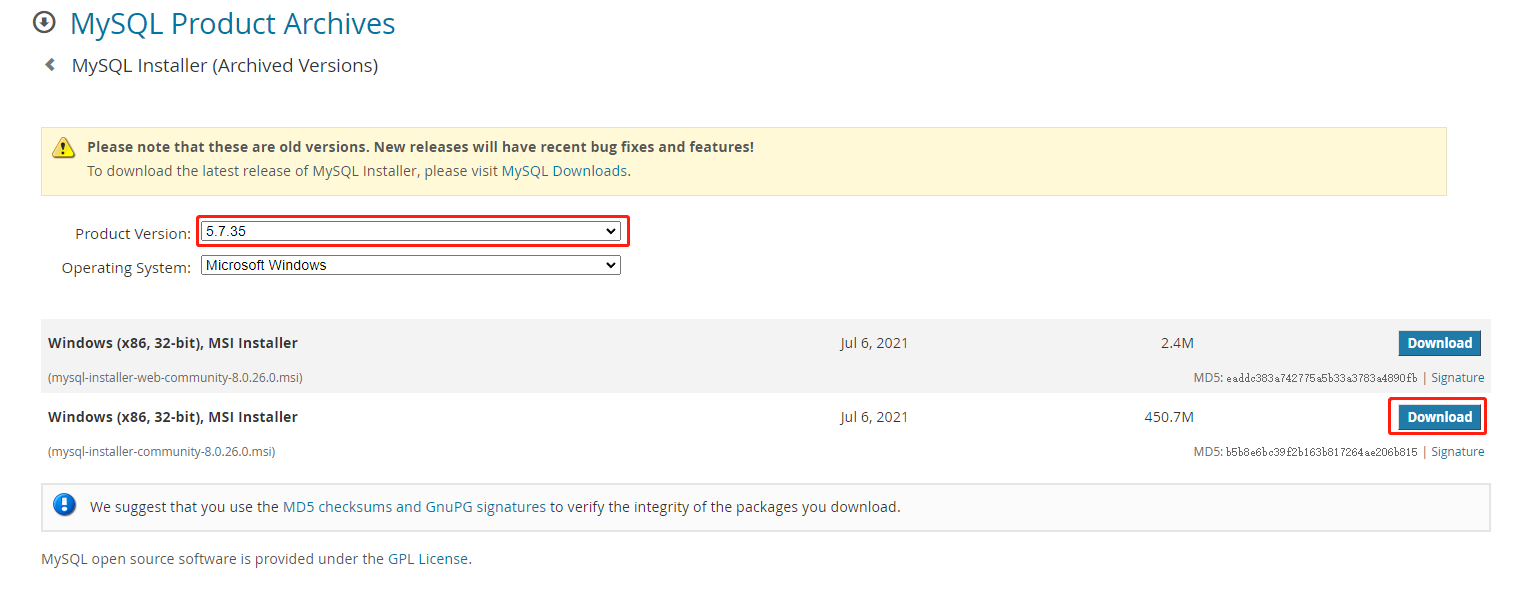
如下图3-1所示
|
||||
|
||||
图 3-1
|
||||
你可以在 https://downloads.mysql.com/archives/installer/ 下载MySql的安装程序。这里建议选择下载的5.7.35版本。
|
||||
|
||||
* 安装MySql
|
||||
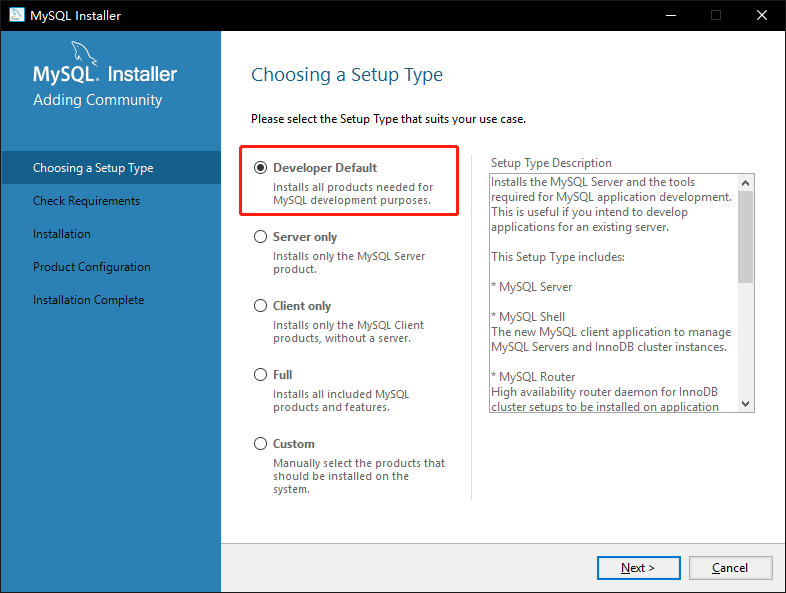
1. 如图3-2所示,双击下载的安装包,选择开发者模式,点击下一步【Next】
|
||||
|
||||
图 3-2
|
||||
|
||||
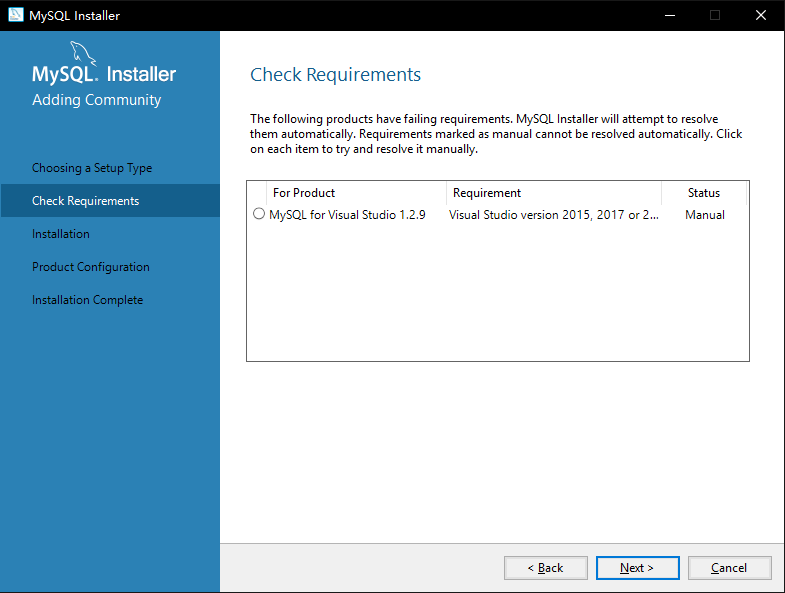
2. 如图3-3,检查依赖库是否安装,点击下一步【Next】
|
||||
|
||||
|
||||
图 3-3
|
||||
|
||||
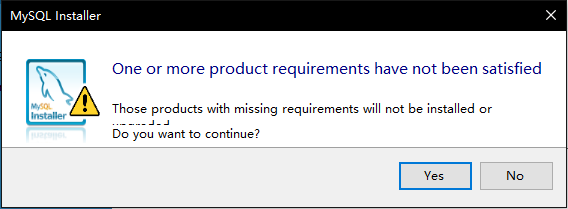
3. 如图3-4,当有依赖软件不满足安装条件,提示是否安装依赖,点击确定【Yes】
|
||||
|
||||
图 3-4
|
||||
|
||||
4. 如图3-5所示,提示将安装下面组件,点击执行【Excute】
|
||||
|
||||
|
||||
图 3-5
|
||||
|
||||
5. 如图3-6所示,安装完成后需要对MySql做对应的配置,配置类型Config Type及端口号Port均不做修改,点击下一步【Next】
|
||||
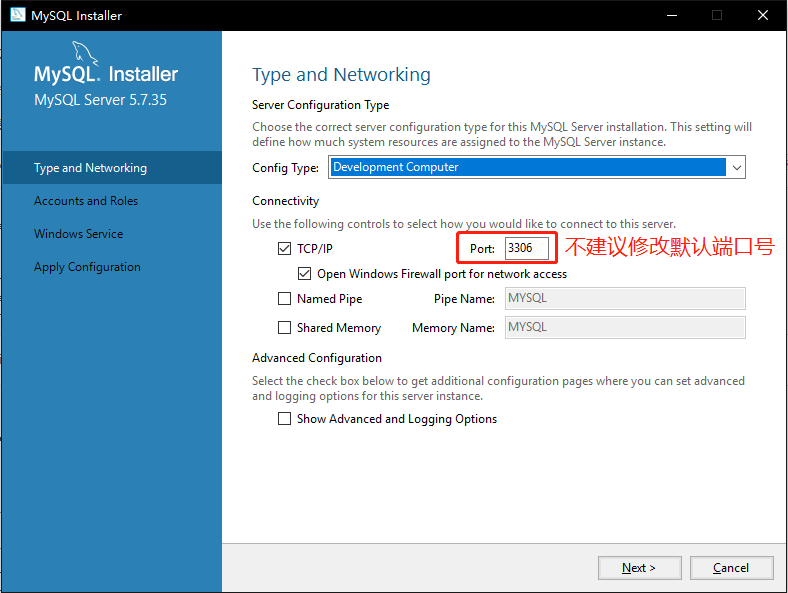
|
||||
图 3-6
|
||||
|
||||
6. 如图3-7所示,需要用户设置MySql root用户的密码,填写密码后点击下一步【Next】
|
||||
|
||||
图 3-7
|
||||
|
||||
7. 如图3-8所示,Windows系统服务配置,默认点击下一步【Next】即可
|
||||
|
||||
图 3-8
|
||||
|
||||
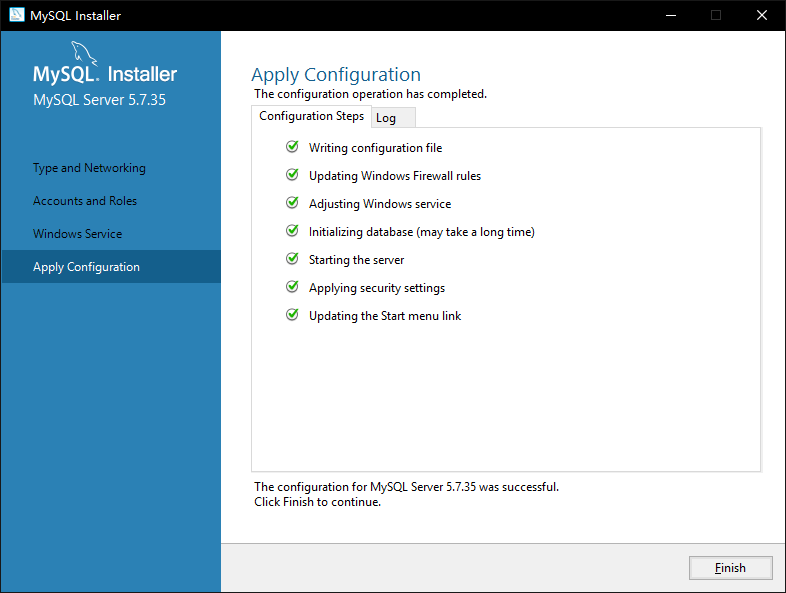
8. 如图3-9所示,等待执行完成后点击完成【Finish】
|
||||
|
||||
图 3-9
|
||||
|
||||
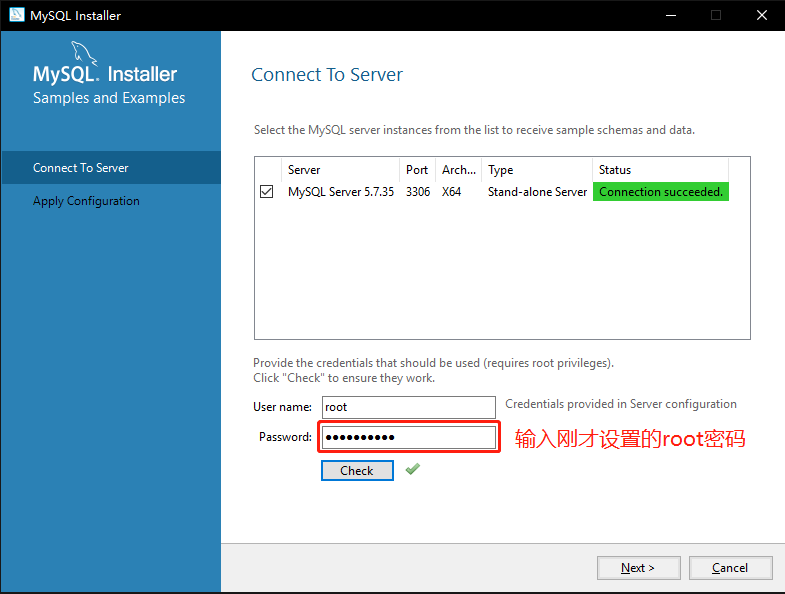
9. 如图3-10所示,安装完成后,输入刚才设置的root密码,点击Check测试安装是否成功,上方连接框中状态Status显示连接成功,说明MySql连接成功,点击下一步【Next】
|
||||
|
||||
图 3-10
|
||||
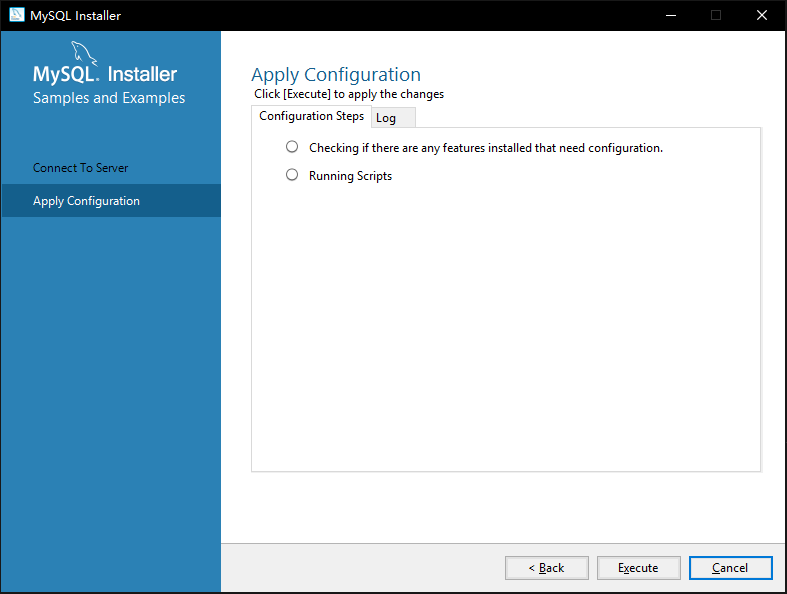
10. 如图3-11所示,待安装程序应用配置执行完成后,点击完成【Finish】完成安装
|
||||
|
||||
|
||||
图 3-11
|
||||
配置完成后,点击下一步,测试MySql服务是否正常启动。最后再次点击【Excute】执行,然后按照引导程序,完成安装过程即可。
|
||||
|
||||
安装完成后,点击【开始】按钮,选择MySql文件夹中的【MySQL 5.7 Command Line Client】,输入密码,即可进入MySql的命令行模式。
|
||||
|
||||
需要说明的是,为了帮助读者能更好地理解SQL语句,本章中所有SQL示例代码片段中以#号开头的语句,均为注释内容。
|
||||
|
||||
在MySql的命令行模式,输入示例3-1中的命令,查看当前的MySql版本号,需要注意的是,语句以分号结束。
|
||||
示例3-1 MySql语句查询版本号
|
||||
```
|
||||
select version();
|
||||
```
|
||||
MySql返回的版本号为:
|
||||
```
|
||||
+------------+
|
||||
| version() |
|
||||
+------------+
|
||||
| 5.7.35-log |
|
||||
+------------+
|
||||
1 row in set
|
||||
```
|
||||
验证MySql安装成功。
|
||||
|
||||
下面的示例3-2,演示了使用Sql语句创建一个test数据库,方便后续的学习测试使用。在MySql命令行模式中,输入创建数据库的Sql语句:
|
||||
示例3-2 创建test数据库
|
||||
```
|
||||
Create DataBase test;
|
||||
```
|
||||
当命令行出现下面的提示,说明数据库创建成功
|
||||
```
|
||||
Query OK, 1 row affected
|
||||
```
|
||||
|
||||
下面通过Sql验证一下test数据库是否创建成功,如示例3-3所示:
|
||||
示例3-3 查询当前连接的MySql服务中所有的数据库
|
||||
```
|
||||
show databases;
|
||||
```
|
||||
如果在输出的结果中,存在test数据库,说明刚才数据库创建成功了。
|
||||
|
||||
```
|
||||
+--------------------+
|
||||
| Database |
|
||||
+--------------------+
|
||||
| information_schema |
|
||||
| mysql |
|
||||
| performance_schema |
|
||||
| sakila |
|
||||
| sys |
|
||||
| test |
|
||||
| world |
|
||||
+--------------------+
|
||||
7 rows in set
|
||||
```
|
||||
|
||||
* 下载数据库连接组件
|
||||
pip是Python提供的一个包安装程序,在安装Python时会默认一同安装,使用pip安装Mysql的连接组件。
|
||||
|
||||
<kbd>Win</kbd> + <kbd>R</kbd> s输入cmd后打开命令行工具,在命令行工具中输入,如示例3-4:
|
||||
示例3-4 安装Python的MySql开发工具
|
||||
```
|
||||
pip install PyMySQL
|
||||
```
|
||||
* 使用MySql的Python连接组件连接数据库
|
||||
|
||||
下载完成后,打开PyCharm,新建项目Chapter3,开始使用Python连接MySql数据库,如示例3-5所示。需要注意的是,代码中的“password”需要输入自己在安装MySql时设置的root密码。
|
||||
示例3-5 Python连接MySql数据库
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 SQL 查询
|
||||
cursor.execute("SELECT VERSION()")
|
||||
# 使用 fetchone() 方法获取单条数据.
|
||||
data = cursor.fetchone()
|
||||
print("MySql的数据库版本是 : %s " % data)
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
|
||||
上面的代码演示了使用pymysql连接数据库,通过执行SELECT VERSION()方法,获取当前MySql数据库版本的流程。
|
||||
|
||||
接下来按照类似的方法,在MySql中创建一个mysql_study表,如示例3-6:
|
||||
|
||||
示例3-6 Python创建MySql数据表
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="*******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 SQL 查询
|
||||
result = cursor.execute('''
|
||||
CREATE TABLE IF NOT EXISTS mysql_study(`id` INT AUTO_INCREMENT ,
|
||||
`name` VARCHAR(100) NOT NULL,
|
||||
`age` INT,
|
||||
PRIMARY KEY (`id`)) default charset = utf8;
|
||||
''')
|
||||
print("数据表创建结果 : %s " % result)
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
数据表的创建结果返回为0,说明创建成功,也可以在MySql的命令行中查询test数据库中的表,确认mysql_study表是否创建成功。
|
||||
```
|
||||
# 设置使用test数据库
|
||||
use test;
|
||||
# 显示当前数据库内所有的表
|
||||
show tables;
|
||||
```
|
||||
### 3.1.2 通过Python对MySQL数据进行增删改
|
||||
|
||||
接下来学习使用pymysql实现对mysql数据库的增删改操作。
|
||||
|
||||
简单来讲,我们对数据库的增删改操作,都是借助于游标cursor执行对应的SQL语句。
|
||||
|
||||
* 新增数据
|
||||
|
||||
示例3-7演示了使用PyMysql连接数据库并在指定的表中插入数据的操作。
|
||||
示例3-7 Python新增MySql数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 插入SQL
|
||||
insertResult = cursor.execute("INSERT INTO mysql_study (name, age) VALUES ('blockchain', 5)")
|
||||
print("新增数据的结果 : %s " % insertResult)
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
新增SQL的返回结果是1,说明这次插入操作成功。可以通过Sql语句在MySql命令行工具中查看代码的执行结果。
|
||||
|
||||
* 修改数据
|
||||
|
||||
示例3-8 Python修改已存在的MySql数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 更新SQL
|
||||
updateResult = cursor.execute('UPDATE mysql_study SET name="blockchain", age = 3 where name="python"')
|
||||
print("更新数据的结果 : %s " % updateResult)
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
上面的示例3-8演示了更新mysql_study表中name是python的数据,修改其name为blockchain,age为3。updateResult的返回值为1说明此次更新操作执行成功,修改了一条数据。再次运行这段代码,因为表中的name已经被修改,不存在name为python的数据,第二次执行的updateResult的结果就是0。
|
||||
|
||||
* 删除数据
|
||||
|
||||
示例3-9 Python删除已存在的MySql数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 删除SQL
|
||||
deleteResult = cursor.execute('DELETE From mysql_study where name="python"')
|
||||
print("删除数据的结果 : %s " % deleteResult)
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
上面的示例3-9演示了删除数据的操作流程,由于SQL语句中给定的Where子句为 name = "python",但是上面的示例我们已经将该条数据的name修改为blockchain,所有deleteResult会返回0。修改where子句为name="blockchain",重新执行后会看到返回结果为1,说明执行成功,删除了一条数据。
|
||||
|
||||
### 3.1.3 通过Python查询MySql数据
|
||||
使用pymsql执行查询操作,同样也是借助于cursor调用fetchXXX()方法来实现。
|
||||
|
||||
* 查询数据
|
||||
|
||||
示例3-10 Python查询MySql的数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 查询SQL
|
||||
cursor.execute('SELECT * FROM mysql_study')
|
||||
# 通过游标获取所有查询到的数据
|
||||
result = cursor.fetchone()
|
||||
while result != None:
|
||||
print(result, cursor.rownumber)
|
||||
result = cursor.fetchone()
|
||||
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
|
||||
上面的示例3-10演示了查询指定表中的所有数据的方法,通过传入的Sql语句,也可以为查询增加where查询字句筛选数据。
|
||||
|
||||
pymysql的cursor查询,提供了3种方法获取查询到的数据:
|
||||
1. fetchone() 获取一条数据
|
||||
2. fetchall() 获取所有查询到的数据
|
||||
3. fetchmany(count) 获取指定条数的数据
|
||||
|
||||
开发者可以根据实际情况调用不同的接口,例如当数据量不大时,可以直接通过fetchall()方法获取到所有的数据,然后再遍历结果即可。如果数据量不大,可以通过fetchmany()方法获取游标后指定个数的数据,当然也可以像上面的例子那样,使用fetchone()查询一条数据。
|
||||
|
||||
另外cursor还提供了scroll()方法,顾名思义,这个方法是让cursor跳过指定条目的数据,这样结合fetchmany()就可以轻松获取到需要翻页显示的数据。
|
||||
## 3.2 Python与非关系型数据库
|
||||
非关系型数据库是相对于传统的关系型数据而言的,意指数据库中的数据相互之间不存在关系,其最常见的解释是“non-relational”(非关系),不过另外一种解释“Not Only SQL”(不仅是结构化查询语言)也被很多人接受。非关系型数据库的主要优点有:易扩展、大数据量、高性能。这些特性非常适合高速发展的互联网行业,目前应用比较广泛的非关系型数据库主要有Redis、MongoDb、HBase等,接下来我们学习如何使用Python来操作MongoDB和Redis数据库。
|
||||
### 3.2.1 Python与MongoDB开发环境准备
|
||||
MongoDB 是一个由C++编写的,基于分布式文件存储的开源数据库系统。它的特点是高性能、易部署、易使用,存储数据方便。类似于关系型数据库中一条数据是以行的形式存在,MongoDB中的每条数据是以文档的形式存在,多个文档组合成为一个文档集合,多个文档集合又组成了MongoDB中的一个数据库。因此当我们需要访问指定的数据时,一般需要通过指定对应的数据库-数据集-文档的方式获取数据。
|
||||
|
||||
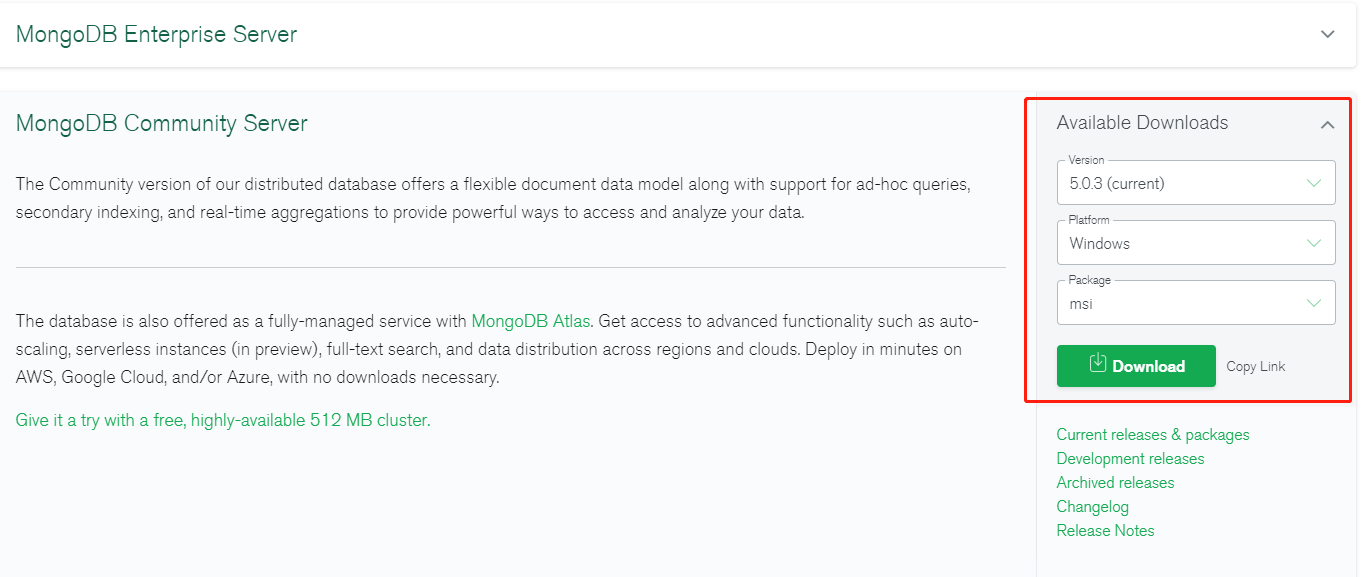
* 安装MongoDB数据库
|
||||
|
||||
|
||||
你可以在MongoDB官网的下载中心(https://www.mongodb.com/try/download/community),下载编译好的安装文件。
|
||||
打开安装文件,按照提示安装即可。
|
||||
|
||||
选择完全安装。
|
||||
|
||||
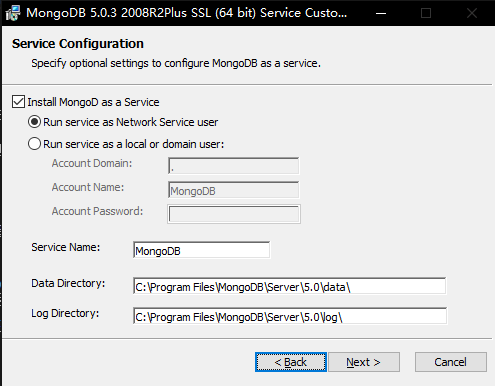
设置MongoDB的服务名、数据目录和Log保存目录,选择下一步,点击【install】安装,等待安装完成。
|
||||
|
||||
* 启动MongoDB数据库
|
||||
打开命令行工具界面,使用命令行启动MongoDB服务
|
||||
```
|
||||
# 进入MongoDB的安装目录,默认为C:\Program Files\MongoDB\Server\5.0\bin
|
||||
cd C:\Program Files\MongoDB\Server\5.0\bin
|
||||
# 启动MOngoDB服务
|
||||
mongod
|
||||
```
|
||||
|
||||
* 简单使用MongoDB客户端
|
||||
服务启动后,默认使用安装时设置的数据库文件路径。接下来可以继续在当前的命令行窗口中连接MongoDB服务:
|
||||
```
|
||||
mongo.exe
|
||||
```
|
||||
|
||||
或双击运行该运行文件,即可进入到Mongo自带的Shell交互环境,连接到本机的MongoDB服务。默认情况下,Mongo Shell会自动连接到test数据库,在Mongo Shell环境下,当一行以大于号开头,说明是用户输入的命令,输入db命令查看当前使用的数据库名称:
|
||||
```
|
||||
> db
|
||||
test
|
||||
```
|
||||
|
||||
MongoDB中的数据是以类似Json的格式来存储的,我们可以通过下面的命令向数据库中插入一条数据:
|
||||
```
|
||||
# 向数据库中插入一条文档数据
|
||||
> db.test.insert({"name":"blockChain"})
|
||||
WriteResult({ "nInserted" : 1 })
|
||||
```
|
||||
上面的示例中,db.test.insert({"name":"blockChain"}) 语句说明我们要向test数据库中插入一条数据{"name":"blockChain"},执行后的结果提示我们此次操作成功插入一条数据。
|
||||
|
||||
接下来我们将插入的数据查询出来:
|
||||
```
|
||||
# 查询数据库中的数据
|
||||
> db.test.find()
|
||||
{ "_id" : ObjectId("61715a409f81ba968524e0da"), "name" : "blockChain" }
|
||||
```
|
||||
通过db.test.find()方法,我们可以查询到所有test内的数据,可以看到,MongoDB自动为我们插入的数据赋值了一个id。
|
||||
|
||||
向当前数据库插入一个数据集。
|
||||
```
|
||||
# 创建一个数据集
|
||||
> db.createCollection("myCollection")
|
||||
{ "ok" : 1 }
|
||||
```
|
||||
|
||||
查询当前数据库中的所有数据集
|
||||
```
|
||||
> show collections
|
||||
myCollection
|
||||
test
|
||||
```
|
||||
|
||||
查询数据集中的文档数据
|
||||
```
|
||||
> db.test.find()
|
||||
{ "_id" : ObjectId("61715a409f81ba968524e0da"), "name" : "blockChain" }
|
||||
> db.myCollection.find()
|
||||
```
|
||||
上面的示例中可以看到,我们此前插入的文档数据默认被写入到test数据集中,而查询myCollection数据集,返回的结果为空。
|
||||
|
||||
### 3.2.2 通过Python操作MongoDB数据库
|
||||
与上面操作MySql类似,通过Python操作MongoDB,也需要先下载MongoDB数据库的连接组件。仍然在命令行工具界面使用pip执行下面的命令:
|
||||
```
|
||||
pip install pymongo
|
||||
```
|
||||
|
||||
* 使用Python连接MongoDB数据库
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取所有的MongoDB数据库
|
||||
dbNameList = mongoClient.list_database_names()
|
||||
# 遍历打印所有的数据库名称
|
||||
for dbName in dbNameList:
|
||||
print(dbName)
|
||||
```
|
||||
上面的例子中,我们使用pymongo连接本地MongoDB服务后,打印出了服务中所有的数据库名称。
|
||||
|
||||
|
||||
* 使用Python创建数据集
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
db.create_collection("testCollection")
|
||||
# 查询数据集
|
||||
for collection in db.list_collections():
|
||||
print(collection)
|
||||
```
|
||||
上面的示例中,演示了连接本地的MongoDB数据库服务,在名为testDB的数据库中创建了testCollection数据集,之后通过db.list_collections()方法获取到指定数据库中的所有数据集,将数据集打印了出来。
|
||||
|
||||
* 使用Python向MongoDB写入文档数据
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 插入一条数据
|
||||
collection.insert_one({"name":"dataTest1", "value": "dataValue1-edit"})
|
||||
# 插入多条数据
|
||||
collection.insert_many([{"name":"dataTest2", "value": "dataValue2"}, {"name":"dataTest3", "value": "dataValue3"}])
|
||||
|
||||
# 查询数据集中的数据
|
||||
for data in collection.find():
|
||||
print(data)
|
||||
```
|
||||
上面的示例演示了使用pymongo向MongoDB数据库中写入数据的方法,pymongo提供了insert_one和insert_many两种插入数据的方法,分别为插入一条数据或多条数据。
|
||||
|
||||
* 使用Python查询MongoDB中的文档数据
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 查询一条数据
|
||||
listData = collection.find()
|
||||
print("查询所有数据的结果:")
|
||||
for data in listData:
|
||||
print(data)
|
||||
|
||||
# 查询name是dataTest2的数据
|
||||
dataTest1 = collection.find({"name": "dataTest2"})
|
||||
print("查询 name = dataTest2的结果:")
|
||||
for data in dataTest1:
|
||||
print(data)
|
||||
```
|
||||
上面的示例演示了使用pymongo查询数据的方法,在数据集对象上调用find()方法即可查询该数据集中的所有数据,如果想要根据条件查询,可以参考下表的表达式查询给定条件的数据。
|
||||
|
||||
|
||||
* 使用Python更新MongoDB中的文档数据
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 更新一条数据,name是dataTest2的数据,修改name的值为dataTest-edit
|
||||
collection.update_one(
|
||||
{'name':'dataTest2'},
|
||||
{'$set':{
|
||||
'name': 'dataTest2-edit'
|
||||
}
|
||||
}
|
||||
)
|
||||
# 更新多条数据,value都被修改为value-edit,新增了一个键值对'anotherValue': 'test'
|
||||
collection.update_many(
|
||||
{},
|
||||
{'$set':{
|
||||
'value': 'value-edit',
|
||||
'anotherValue': 'test'
|
||||
}
|
||||
}
|
||||
)
|
||||
# 查询所有数据
|
||||
dataTest1 = collection.find({})
|
||||
print("查询 name = dataTest2的结果:")
|
||||
for data in dataTest1:
|
||||
print(data)
|
||||
```
|
||||
|
||||
* 使用Python删除MongoDB中的文档数据
|
||||
```python
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 删除一条数据,删除name的值为dataTest-edit的数据
|
||||
deleteOneResult = collection.delete_one({
|
||||
'name': 'dataTest2-edit'
|
||||
})
|
||||
print("删除一个数据的结果:"+ str(deleteOneResult.raw_result))
|
||||
|
||||
# 删除多条数据,删除name是dataTest开头的所有数据
|
||||
deleteManyResult = collection.delete_many(
|
||||
{
|
||||
'name': {'$regex': 'dataTest'}
|
||||
}
|
||||
)
|
||||
|
||||
print("删除多个数据的结果:"+ str(deleteManyResult.raw_result))
|
||||
|
||||
# 查询name是dataTest2的数据
|
||||
dataTest1 = collection.find({})
|
||||
print("查询 name = dataTest2的结果:")
|
||||
for data in dataTest1:
|
||||
print(data)
|
||||
```
|
||||
|
||||
### 3.2.3 Python与Redis开发环境准备
|
||||
|
||||
Redis是一个开源的、遵守 BSD 开源协议,是一个高性能的 key-value 数据库。它支持数据的持久化,它不仅支持简单数据类型的保存,还对list、set等复杂数据类型也有很好的支持。
|
||||
Redis有着极高的读写效率,读取速率可达110000次/秒,写入速率也有高达80000次/秒,因此Redis数据库也常被用来作为程序中缓存数据的读写方案。
|
||||
|
||||
* 安装Redis
|
||||
你可以在Redis github的Release页面(https://github.com/tporadowski/redis/releases)下载最新的安装程序。
|
||||
|
||||
打开安装程序,按照提示安装程序
|
||||
|
||||
可修改Redis的安装目录,以及将Redis的安装目录添加到环境变量path中。
|
||||
|
||||
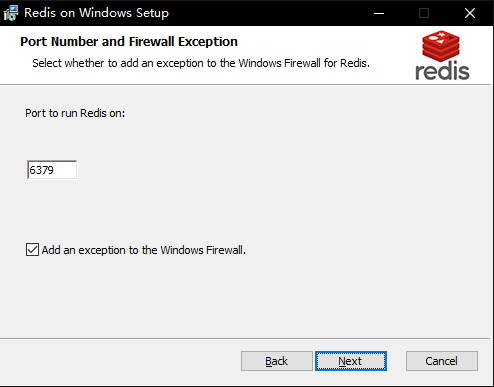
Redis的默认端口号为6379。
|
||||
|
||||
* 简单使用Redis
|
||||
打开命令行工具界面,进入到redis的安装目录,启动Redis服务,保持该界面为打开状态
|
||||
```
|
||||
# 进入Redis的安装路径中
|
||||
cd C:\Program Files\Redis
|
||||
|
||||
# 启动Redis服务
|
||||
redis-server.exe redis.windows.conf
|
||||
```
|
||||
如下图所示,说明Redis服务已经启动成功,保持该界面为打开状态。
|
||||
|
||||
|
||||
重新打开一个命令行工具界面,进入Redis安装目录后,使用Redis新增、查询数据。
|
||||
```
|
||||
# 进入Redis的安装路径中
|
||||
cd C:\Program Files\Redis
|
||||
|
||||
# 进入redis客户端命令行模式
|
||||
redis-cli
|
||||
|
||||
# 向Redis中存储数据:myKey-myValue
|
||||
127.0.0.1:6379> set myKey myValue
|
||||
# 存储成功
|
||||
OK
|
||||
# 获取myKey对应的值
|
||||
127.0.0.1:6379> get myKey
|
||||
# 获取成功
|
||||
"myValue"
|
||||
```
|
||||
### 3.2.4 通过Python操作Redis数据库
|
||||
与上述章节类似,接下来我们学习使用Python代码操作Redis数据库。
|
||||
|
||||
在命令行工具中,执行以下语句,下载Redis的连接组件。
|
||||
```
|
||||
pip install redis
|
||||
```
|
||||
|
||||
* 使用Python向Redis数据库中写入数据
|
||||
```
|
||||
import redis
|
||||
# 连接Redis数据库,host为Redis服务地址,port为Redis服务端口,encoding为编码格式,db为连接的数据库名称-默认名称为0
|
||||
conn = redis.Redis(host='localhost', port='6379', encoding='utf-8', db=0)
|
||||
# 写入值
|
||||
# 其他参数说明
|
||||
# nx-如果设置为True,则只有key不存在时,当前set操作才执行,同#setnx(key, value)
|
||||
# xx-如果设置为True,则只有key存在时,当前set操作才执行,同setxx(key, value)
|
||||
# ex-过期时间(秒)
|
||||
# px-过期时间(毫秒)
|
||||
conn.set("blockChain", "good")
|
||||
# 写入值,当key不存在时才执行
|
||||
conn.set("blockChain", "very good", nx=True)
|
||||
# 批量设置值
|
||||
conn.mset({"mkey1":'mvalue1', "mkey2":'mvalue2'})
|
||||
```
|
||||
上面的例子中,我们在连接redis数据库后,通过set(key, value)方法向redis中写入数据。程序也支持批量写入数据,可以很方便地将Python的Dict数据按照k-v的格式存储到Redis数据库中。
|
||||
|
||||
由于Redis是k-v数据库,对数据库的更新与插入,操作流程几乎相同,根据指定的key是否存在而是否执行写入操作,就可以控制数据库的更新与插入是否执行。
|
||||
|
||||
上面的例子中,我们对blockChain执行了两次写入操作,第二次增加了nx=True的参数,读者朋友可以测试一下,程序执行结束后,blockChain对应的值是什么?
|
||||
|
||||
* 使用Redis查询数据
|
||||
```
|
||||
import redis
|
||||
# 连接Redis数据库,host为Redis服务地址,port为Redis服务端口,encoding为编码格式,db为连接的数据库名称-默认名称为0
|
||||
conn = redis.Redis(host='localhost', port='6379', encoding='utf-8', db=0)
|
||||
# 读取值
|
||||
print("blockChain的值是:", conn.get("blockChain"))
|
||||
# 批量读取值
|
||||
mValues = conn.mget(("mkey1", "mkey2"))
|
||||
for value in mValues:
|
||||
print(value)
|
||||
```
|
||||
|
||||
上述示例演示了使用Python读取Redis数据库内数据的方法,同写入数据类似,也支持单个读取get(key)和批量读取mget((key1, key2...))数据,开发者可以轻松使用这些接口实现对Redis数据库的读取操作。
|
||||
## 疑难解答
|
||||
### 1. 为什么一定要使用数据库?
|
||||
我们知道,程序是运行在计算机的内存中的,当程序退出或计算机关闭后,程序执行的结果也就随之消失了。但是实际业务中经常需要让程序在下一次运行时仍然可以获取到上一次的执行结果,这个时候我们就需要将运行的结果“持久化”保存起来,这就是所谓的“持久化”。
|
||||
|
||||
例如一个学生信息管理系统,需要记录每个学生的学号、姓名以及各科成绩,每次考试都需要记录学生的考试成绩。程序不可能在几年的时间中一直保持运行,就需要将这些信息保存到硬盘中。如果这个系统中维护的数据仅仅是一个班的几十名同学的数据,那么使用文本文件来保存也未尝不可,但是当程序要维护的学生数据是整个省的数十万的学生数据,使用这样的方式就会极为不方便,由于各个学校考试时间不同,很多时候只是要更新某一个学校学生的数据,这个时候就需要被保存的数据还可以支持方便的查询、修改、删除的操作,而这些功能,就是一个数据库管理系统最擅长的领域,这也是程序必须使用数据库的原因。
|
||||
### 2. 关系型数据库和非关系型数据库的差异?
|
||||
关系型数据库中保存的都是以结构化数据为主,每个结构化数据组成一张表,各个表之间通过主键、外键相互关联。结构化数据库的优点是符合大多数的业务认知,维护起来相对简单,使用也十分方便,缺点就是读写效率较慢,表结构因为相互关联,灵活度相对不足。这些缺点恰好就是高速发展的互联网行业的最大痛点,多数互联网行业业务都是高速发展的,需要频繁地更新表结构,而且因为面对个人群体,用户量也极为庞大,这些特点注定了他们需要一种不仅仅可以完美支持可以支持高并发、大数据量并且可以灵活变更数据结构的数据库,这也就诞生了“No SQL”——非关系型数据库。
|
||||
|
||||
非关系型数据库弥补了关系型数据库的缺点,但是学习和使用成本则相对较高,除此之外,非关系型数据库没有对事务的支持,同时相比于关系型数据库,查询方式也较为简单。可以说,两种数据库互有优劣,使用时根据各自的业务需要,选择适合自己的数据库即可。
|
||||
|
||||
## 实训:抓取视频和新闻网站的数据
|
||||
这里我们以抓取登链社区(https://learnblockchain.cn/)的精选文章为例,演示如何使用Python抓取网站数据并将抓取到的数据保存在数据库中。登链社区是一群区块链技术爱好者共同维护的社区,也是国内区块链较为知名的社区之一。网站开放以来累计服务了超过百万的读者,社区以高质量的内容得到广大读者的好评。
|
||||
|
||||
以下图为例,进入到登链社区的精选文章页面,通过切换页码,会发现分页链接以较为规律的形式形成,通过参数page来设置当前所处的页数,下面以抓取精选文章前20页的文章内容为例。
|
||||
|
||||
抓取文章数据,需要依靠下面的几个开放组件完成,下面主要介绍一下各个组件在抓取数据流程中的作用。
|
||||
url包:提供了request工具获取指定url对应的html源码,通过html源码来获取需要抓取的信息。
|
||||
bs4包:提供了BeautifulSoap工具,可以方便地从html源码中解析需要的数据。
|
||||
|
||||
```
|
||||
# -*- codeing = utf-8 -*-
|
||||
from bs4 import BeautifulSoup # 网页解析,获取数据
|
||||
import urllib.request, urllib.error # 制定URL,获取网页数据
|
||||
import pymysql # mysql数据库
|
||||
|
||||
mysqlDB = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
cursor = mysqlDB.cursor()
|
||||
|
||||
# 定义抓取页面的主方法
|
||||
# startPage为抓取的其实页, endPage为抓取的结束页
|
||||
def main(startPage, endPage):
|
||||
# 定义抓取的起始页
|
||||
startUrl = "https://learnblockchain.cn/categories/all/featured?page={num}"
|
||||
for page in range(startPage, endPage+1):
|
||||
# 获取到指定url的html源码
|
||||
html = getUrlHtml(startUrl.replace("{num}", str(page)))
|
||||
# 调用Jsoup对html源码解析,获取需要的标题内容数据
|
||||
titleBlockList = getTitleBlock(html)
|
||||
# 使用正则表达式解析标题代码块内的内容,并且将数据保存在对象中
|
||||
for item in titleBlockList:
|
||||
# 使用dict记录需要被保存的数据
|
||||
dataDict = {}
|
||||
# 获取h2标签内容,从中解析标题内容及链接
|
||||
titleSoup = BeautifulSoup(str(item), "html5lib")
|
||||
|
||||
# 在代码块中获取h2的标签,即为标题标签,可以获取到标题的文本内容和链接
|
||||
titleTag = titleSoup.find(name="h2", class_="title")
|
||||
# 获取titleTag中的超链接a标签,获取链接地址和标题文本
|
||||
title = titleTag.find(name="a")
|
||||
dataDict["title"] = title.string
|
||||
dataDict["href"] = title["href"]
|
||||
|
||||
# 从item里获取标题中的描述性文字
|
||||
descriptionTag = titleSoup.find(name="p")
|
||||
if descriptionTag != None:
|
||||
dataDict["description"] = descriptionTag.string
|
||||
|
||||
# 从item里获取作者信息
|
||||
authorTag = titleSoup.find(name="ul", class_="author")
|
||||
if authorTag!=None:
|
||||
dataDict["author"] = authorTag.find(name="a").text
|
||||
|
||||
# 将map数据保存到mysql数据库中
|
||||
saveIntoMySql(dataDict)
|
||||
|
||||
|
||||
# 得到指定一个URL的网页内容
|
||||
def getUrlHtml(url):
|
||||
request = urllib.request.Request(url)
|
||||
html = ""
|
||||
try:
|
||||
response = urllib.request.urlopen(request)
|
||||
html = response.read().decode("utf-8")
|
||||
except urllib.error.URLError as e:
|
||||
if hasattr(e, "code"):
|
||||
print(e.code)
|
||||
if hasattr(e, "reason"):
|
||||
print(e.reason)
|
||||
return html
|
||||
|
||||
# 获取标题列表页面中所有的标题代码块
|
||||
def getTitleBlock(html):
|
||||
beautifulSoup = BeautifulSoup(html, features="html.parser")
|
||||
# 定义一个数组,保存所有的标题内容
|
||||
resultSet = beautifulSoup.find_all('section', class_="stream-list-item") # 查找符合要求的字符串
|
||||
return resultSet
|
||||
|
||||
# 将数据保存到MySql数据库中
|
||||
def saveIntoMySql(dataDict):
|
||||
# 定义插入数据库的语句
|
||||
sqlstr = '''INSERT INTO test.learnblockchain
|
||||
(title, href, description, author)
|
||||
VALUES
|
||||
("{title}", "{href}", "{description}", "{author}")
|
||||
'''
|
||||
# 格式化sql语句,将数据内容替换到sql语句中
|
||||
try:
|
||||
sqlstr = sqlstr.format(title=dataDict['title'].strip(), href=dataDict['href'].strip(), description=dataDict['description'].strip(), author=dataDict['author'].strip())
|
||||
result = cursor.execute(sqlstr)
|
||||
mysqlDB.commit()
|
||||
# 执行插入操作
|
||||
print("插入结果:", result)
|
||||
except BaseException as e:
|
||||
print(e)
|
||||
|
||||
# 初始化MySql数据库,建表
|
||||
def initMySql():
|
||||
# 打开数据库连接
|
||||
createTableResult = cursor.execute('''
|
||||
CREATE TABLE IF NOT EXISTS test.learnblockchain(`id` INT AUTO_INCREMENT ,
|
||||
`title` VARCHAR(300) NOT NULL,
|
||||
`href` VARCHAR(300) NOT NULL,
|
||||
`description` VARCHAR(300) NOT NULL,
|
||||
`author` VARCHAR(50) NOT NULL,
|
||||
PRIMARY KEY (`id`))
|
||||
default charset = utf8;
|
||||
''')
|
||||
mysqlDB.commit()
|
||||
return createTableResult,mysqlDB
|
||||
|
||||
if __name__ == "__main__": # 当程序执行时
|
||||
initMySql()
|
||||
# 调用函数
|
||||
main(1, 2)
|
||||
print("数据抓取完毕!")
|
||||
if mysqlDB != None:
|
||||
mysqlDB.close()
|
||||
```
|
||||
上面的示例中仅仅抓取了网站内的精选文章板块,并且只抓取了文章列表的标题、文章访问地址、内容简介以及作者,并且将抓取的数据保存在MySql数据库中。有兴趣的读者可以在此基础上尝试修改示例,根据文章访问地址获取到文章的全部文本内容,然后将抓取到的数据保存在MongoDB数据库中。
|
||||
|
||||
## 本章总结
|
||||
本章主要介绍了使用Python对MySql、MongoDB和Redis等数据库做一些简单的增删改查操作,数据库可以说是一个应用程序的基础,因为程序本质就是处理数据的输入输出以及对数据做必要的逻辑处理,而Python对各种数据库的支持也堪称全面,使用pysql基本可以满足绝大多数的业务需求。
|
||||
Reference in New Issue
Block a user