fix: 增加日记记录
This commit is contained in:
0
language/Python区块链/.nojekyll
Normal file
0
language/Python区块链/.nojekyll
Normal file
BIN
language/Python区块链/Python与数据库.docx
Normal file
BIN
language/Python区块链/Python与数据库.docx
Normal file
Binary file not shown.
715
language/Python区块链/Python与数据库.md
Normal file
715
language/Python区块链/Python与数据库.md
Normal file
@@ -0,0 +1,715 @@
|
||||
# 第3章 Python与数据库
|
||||
Python程序一般是运行在内存中,当程序停止时运行的结果也就随之消失了。想要将运行的结果保存起来,如果数据量比较少,可以借助此前提到的IO操作写入到文本文件中或Excel中,但是如果数据量比较大,还有运行时期望对数据进行筛选操作,就需要用到数据库。
|
||||
|
||||
Python对各种类型数据库的读写都提供了完善的支持,一般对数据库的增、删、改、查操作在Python中实现起来也并不复杂,下面我们简单介绍一下使用Python读写关系型数据库Mysql和非关系型数据库MongoDB及Redis的方法。
|
||||
## 3.1 Python与关系型数据库
|
||||
关系型数据库,顾名思义,是指以关系模型来组织数据的数据库,数据库中一般以行和列的形式存储数据,以便于用户理解。一系列的行和列组成了表,而多个表共同组成了数据库。用户查询数据时通过指定表内列的条件,获取到所有符合条件的行数据。
|
||||
|
||||
关系模型可以理解为二维的表格模型,关系型数据库就是由多个二维表格和表格间的关系组成。一般常用的关系型数据库有MySql、Oracle、Sqlite和PostgreSql等。
|
||||
|
||||
下面我们以Mysql为例,学习如何使用Python操作关系型数据库。
|
||||
### 3.1.1 Python与MySQL开发环境准备
|
||||
* 下载MySql
|
||||
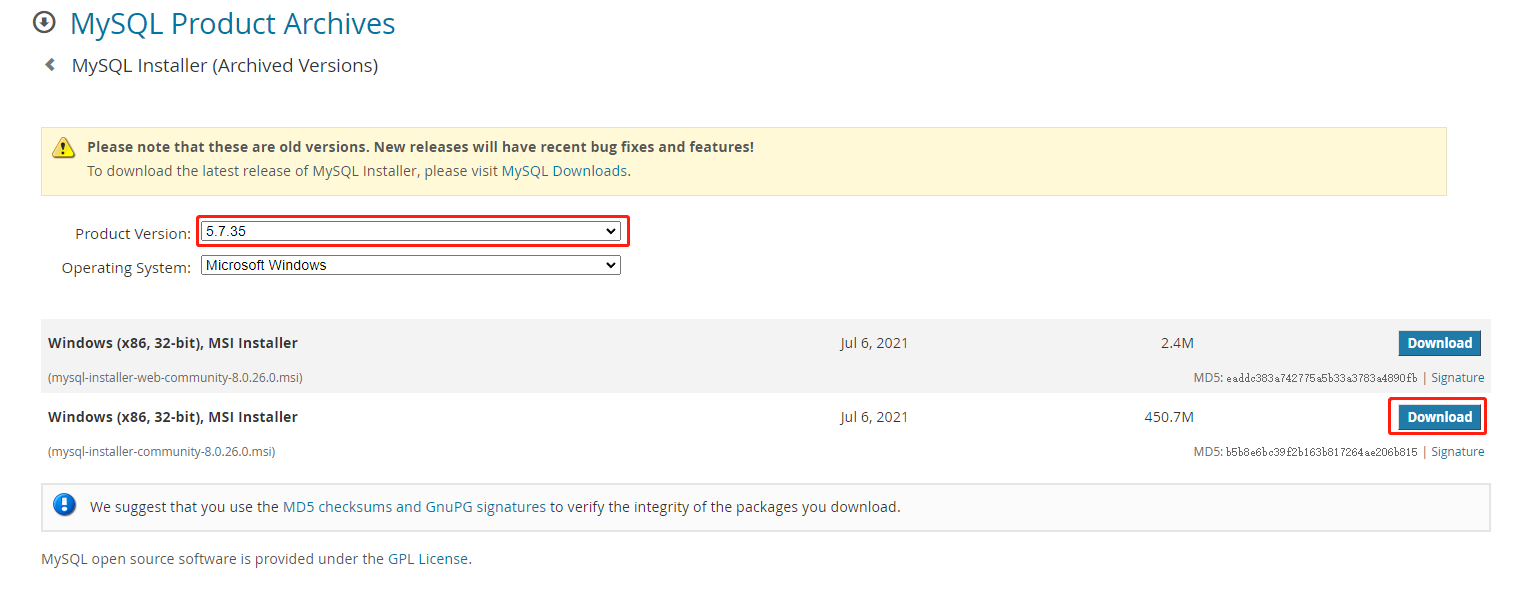
如下图3-1所示
|
||||
|
||||
图 3-1
|
||||
你可以在 https://downloads.mysql.com/archives/installer/ 下载MySql的安装程序。这里建议选择下载的5.7.35版本。
|
||||
|
||||
* 安装MySql
|
||||
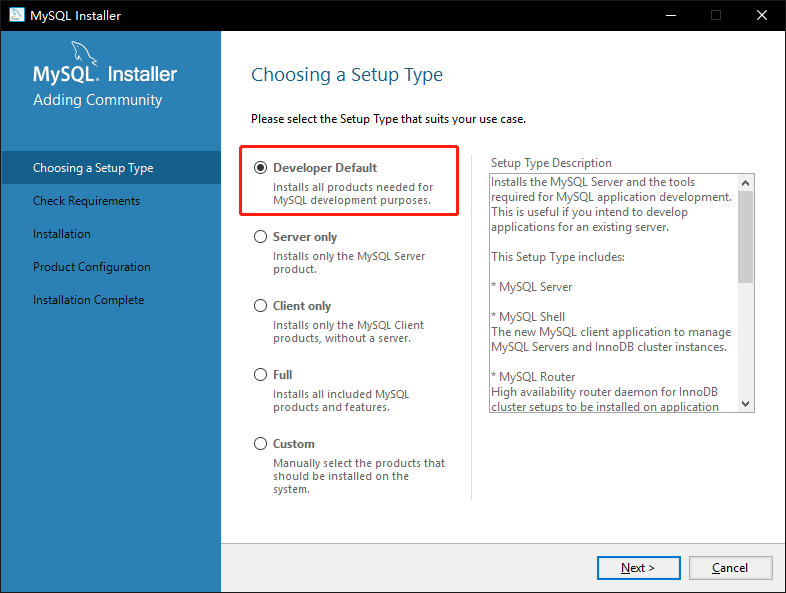
1. 如图3-2所示,双击下载的安装包,选择开发者模式,点击下一步【Next】
|
||||
|
||||
图 3-2
|
||||
|
||||
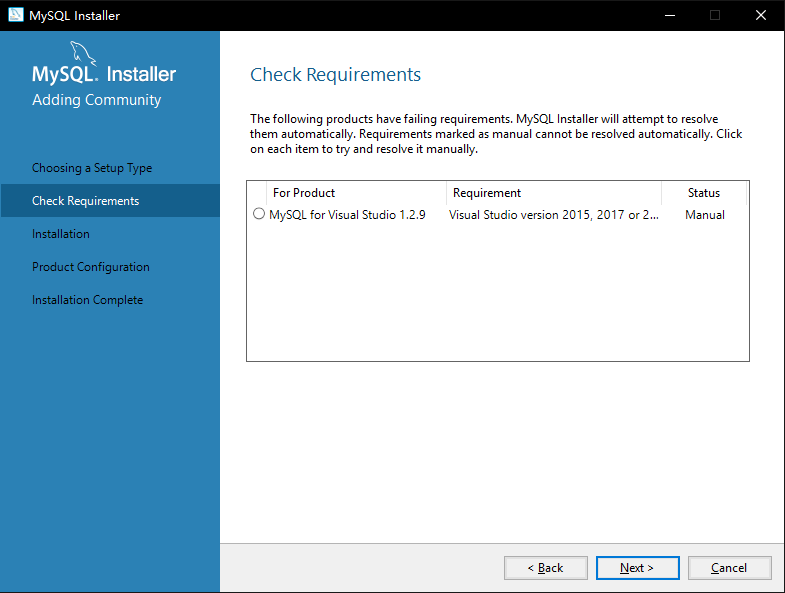
2. 如图3-3,检查依赖库是否安装,点击下一步【Next】
|
||||
|
||||
|
||||
图 3-3
|
||||
|
||||
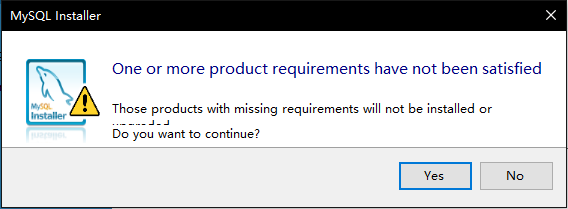
3. 如图3-4,当有依赖软件不满足安装条件,提示是否安装依赖,点击确定【Yes】
|
||||
|
||||
图 3-4
|
||||
|
||||
4. 如图3-5所示,提示将安装下面组件,点击执行【Excute】
|
||||
|
||||
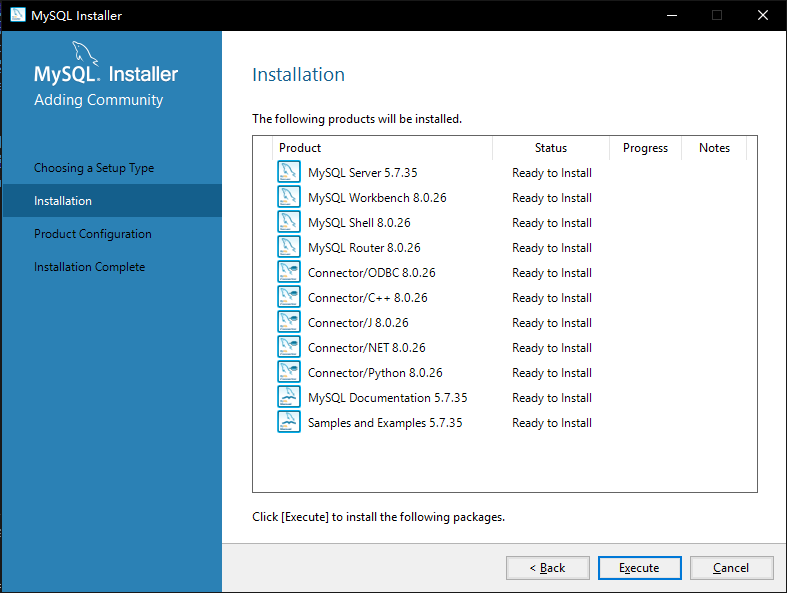
|
||||
图 3-5
|
||||
|
||||
5. 如图3-6所示,安装完成后需要对MySql做对应的配置,配置类型Config Type及端口号Port均不做修改,点击下一步【Next】
|
||||
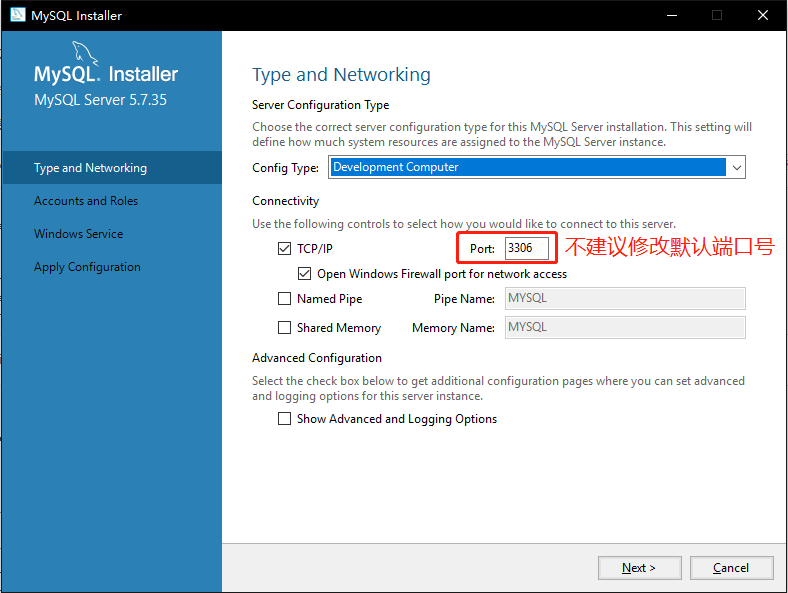
|
||||
图 3-6
|
||||
|
||||
6. 如图3-7所示,需要用户设置MySql root用户的密码,填写密码后点击下一步【Next】
|
||||
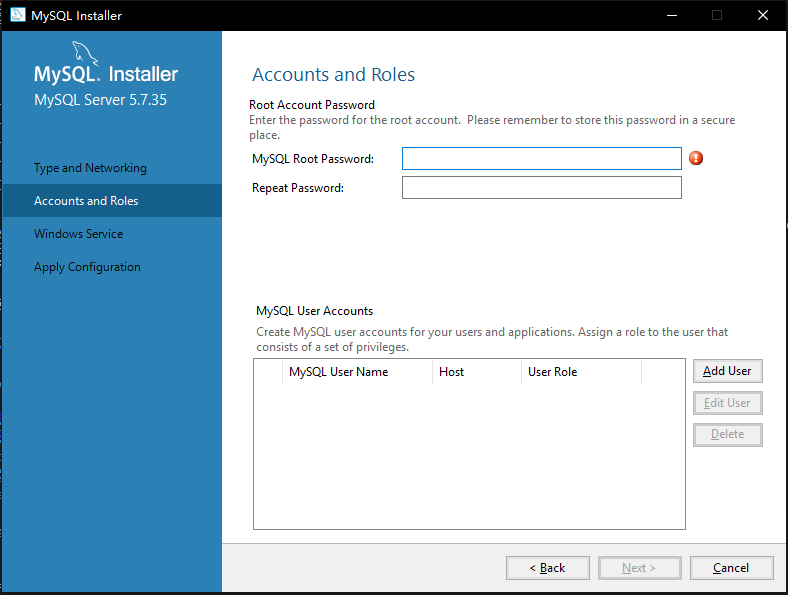
|
||||
图 3-7
|
||||
|
||||
7. 如图3-8所示,Windows系统服务配置,默认点击下一步【Next】即可
|
||||
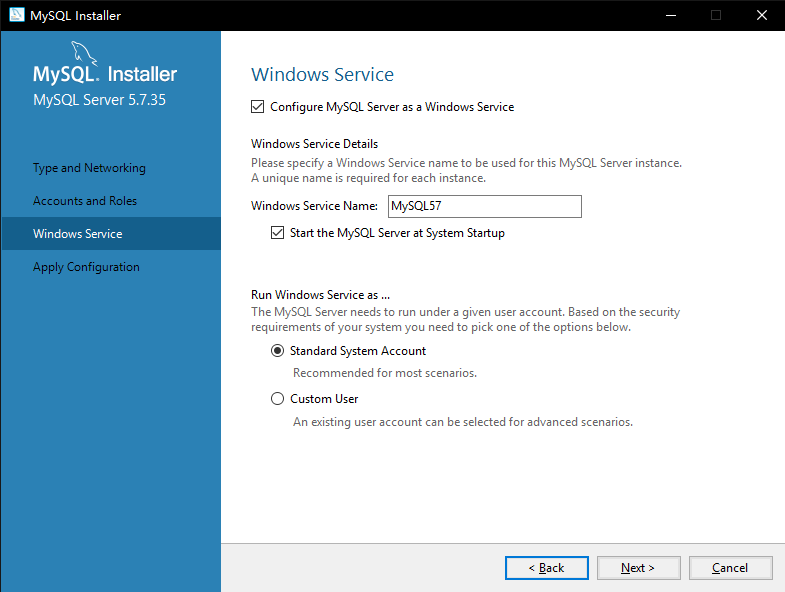
|
||||
图 3-8
|
||||
|
||||
8. 如图3-9所示,等待执行完成后点击完成【Finish】
|
||||
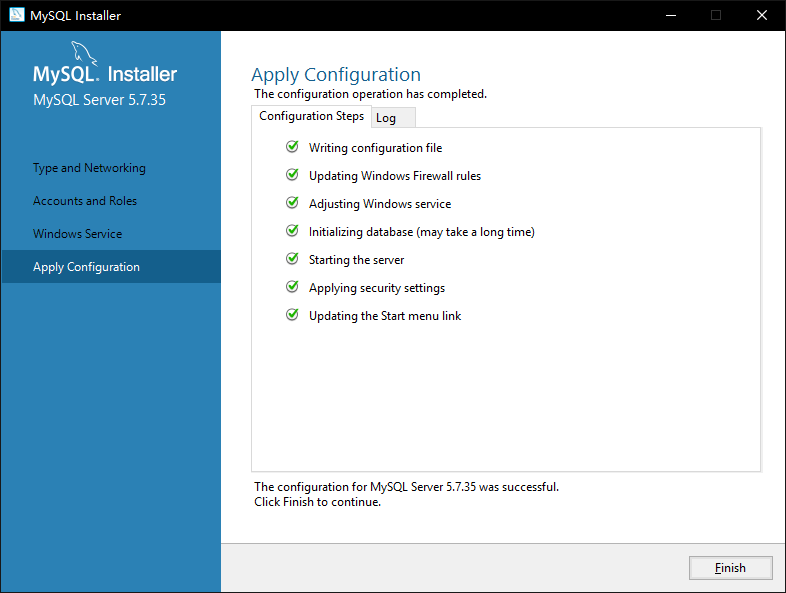
|
||||
图 3-9
|
||||
|
||||
9. 如图3-10所示,安装完成后,输入刚才设置的root密码,点击Check测试安装是否成功,上方连接框中状态Status显示连接成功,说明MySql连接成功,点击下一步【Next】
|
||||
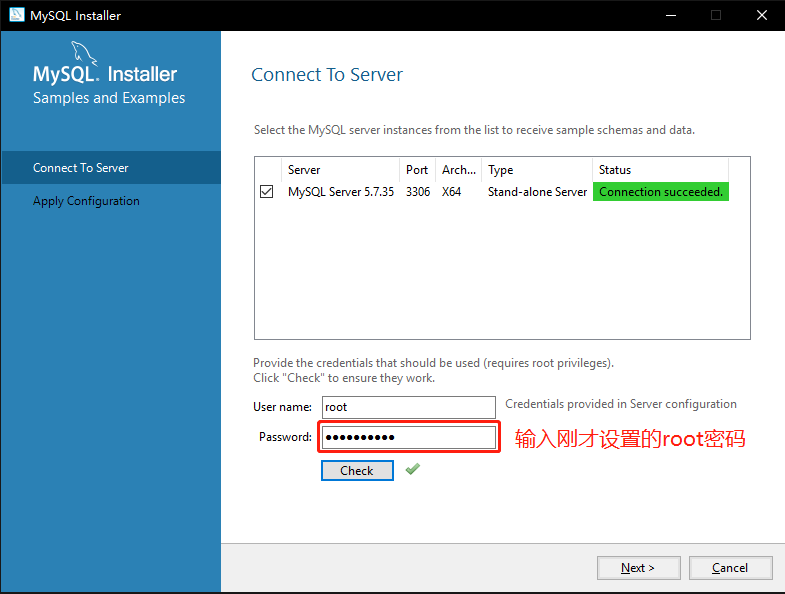
|
||||
图 3-10
|
||||
10. 如图3-11所示,待安装程序应用配置执行完成后,点击完成【Finish】完成安装
|
||||
|
||||
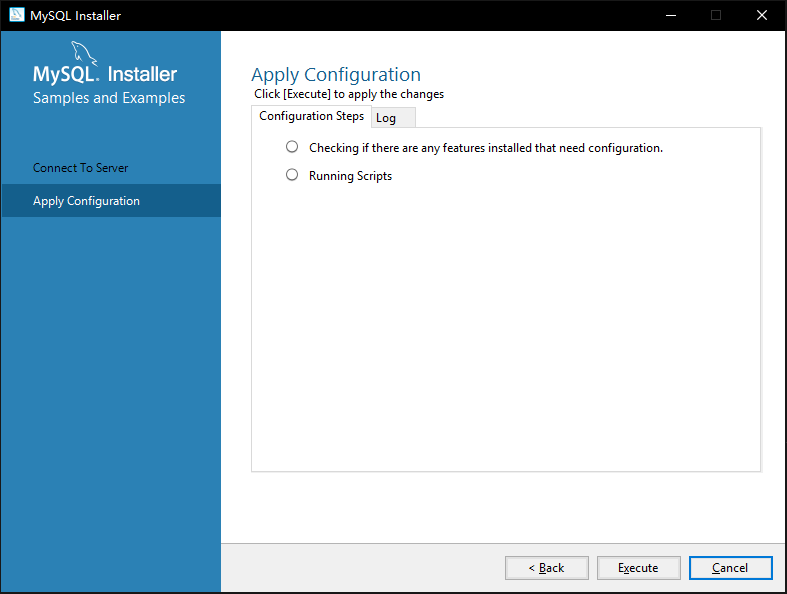
|
||||
图 3-11
|
||||
配置完成后,点击下一步,测试MySql服务是否正常启动。最后再次点击【Excute】执行,然后按照引导程序,完成安装过程即可。
|
||||
|
||||
安装完成后,点击【开始】按钮,选择MySql文件夹中的【MySQL 5.7 Command Line Client】,输入密码,即可进入MySql的命令行模式。
|
||||
|
||||
需要说明的是,为了帮助读者能更好地理解SQL语句,本章中所有SQL示例代码片段中以#号开头的语句,均为注释内容。
|
||||
|
||||
在MySql的命令行模式,输入示例3-1中的命令,查看当前的MySql版本号,需要注意的是,语句以分号结束。
|
||||
示例3-1 MySql语句查询版本号
|
||||
```
|
||||
select version();
|
||||
```
|
||||
MySql返回的版本号为:
|
||||
```
|
||||
+------------+
|
||||
| version() |
|
||||
+------------+
|
||||
| 5.7.35-log |
|
||||
+------------+
|
||||
1 row in set
|
||||
```
|
||||
验证MySql安装成功。
|
||||
|
||||
下面的示例3-2,演示了使用Sql语句创建一个test数据库,方便后续的学习测试使用。在MySql命令行模式中,输入创建数据库的Sql语句:
|
||||
示例3-2 创建test数据库
|
||||
```
|
||||
Create DataBase test;
|
||||
```
|
||||
当命令行出现下面的提示,说明数据库创建成功
|
||||
```
|
||||
Query OK, 1 row affected
|
||||
```
|
||||
|
||||
下面通过Sql验证一下test数据库是否创建成功,如示例3-3所示:
|
||||
示例3-3 查询当前连接的MySql服务中所有的数据库
|
||||
```
|
||||
show databases;
|
||||
```
|
||||
如果在输出的结果中,存在test数据库,说明刚才数据库创建成功了。
|
||||
|
||||
```
|
||||
+--------------------+
|
||||
| Database |
|
||||
+--------------------+
|
||||
| information_schema |
|
||||
| mysql |
|
||||
| performance_schema |
|
||||
| sakila |
|
||||
| sys |
|
||||
| test |
|
||||
| world |
|
||||
+--------------------+
|
||||
7 rows in set
|
||||
```
|
||||
|
||||
* 下载数据库连接组件
|
||||
pip是Python提供的一个包安装程序,在安装Python时会默认一同安装,使用pip安装Mysql的连接组件。
|
||||
|
||||
<kbd>Win</kbd> + <kbd>R</kbd> s输入cmd后打开命令行工具,在命令行工具中输入,如示例3-4:
|
||||
示例3-4 安装Python的MySql开发工具
|
||||
```
|
||||
pip install PyMySQL
|
||||
```
|
||||
* 使用MySql的Python连接组件连接数据库
|
||||
|
||||
下载完成后,打开PyCharm,新建项目Chapter3,开始使用Python连接MySql数据库,如示例3-5所示。需要注意的是,代码中的“password”需要输入自己在安装MySql时设置的root密码。
|
||||
示例3-5 Python连接MySql数据库
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 SQL 查询
|
||||
cursor.execute("SELECT VERSION()")
|
||||
# 使用 fetchone() 方法获取单条数据.
|
||||
data = cursor.fetchone()
|
||||
print("MySql的数据库版本是 : %s " % data)
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
|
||||
上面的代码演示了使用pymysql连接数据库,通过执行SELECT VERSION()方法,获取当前MySql数据库版本的流程。
|
||||
|
||||
接下来按照类似的方法,在MySql中创建一个mysql_study表,如示例3-6:
|
||||
|
||||
示例3-6 Python创建MySql数据表
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="*******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 SQL 查询
|
||||
result = cursor.execute('''
|
||||
CREATE TABLE IF NOT EXISTS mysql_study(`id` INT AUTO_INCREMENT ,
|
||||
`name` VARCHAR(100) NOT NULL,
|
||||
`age` INT,
|
||||
PRIMARY KEY (`id`)) default charset = utf8;
|
||||
''')
|
||||
print("数据表创建结果 : %s " % result)
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
数据表的创建结果返回为0,说明创建成功,也可以在MySql的命令行中查询test数据库中的表,确认mysql_study表是否创建成功。
|
||||
```
|
||||
# 设置使用test数据库
|
||||
use test;
|
||||
# 显示当前数据库内所有的表
|
||||
show tables;
|
||||
```
|
||||
### 3.1.2 通过Python对MySQL数据进行增删改
|
||||
|
||||
接下来学习使用pymysql实现对mysql数据库的增删改操作。
|
||||
|
||||
简单来讲,我们对数据库的增删改操作,都是借助于游标cursor执行对应的SQL语句。
|
||||
|
||||
* 新增数据
|
||||
|
||||
示例3-7演示了使用PyMysql连接数据库并在指定的表中插入数据的操作。
|
||||
示例3-7 Python新增MySql数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 插入SQL
|
||||
insertResult = cursor.execute("INSERT INTO mysql_study (name, age) VALUES ('blockchain', 5)")
|
||||
print("新增数据的结果 : %s " % insertResult)
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
新增SQL的返回结果是1,说明这次插入操作成功。可以通过Sql语句在MySql命令行工具中查看代码的执行结果。
|
||||
|
||||
* 修改数据
|
||||
|
||||
示例3-8 Python修改已存在的MySql数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 更新SQL
|
||||
updateResult = cursor.execute('UPDATE mysql_study SET name="blockchain", age = 3 where name="python"')
|
||||
print("更新数据的结果 : %s " % updateResult)
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
上面的示例3-8演示了更新mysql_study表中name是python的数据,修改其name为blockchain,age为3。updateResult的返回值为1说明此次更新操作执行成功,修改了一条数据。再次运行这段代码,因为表中的name已经被修改,不存在name为python的数据,第二次执行的updateResult的结果就是0。
|
||||
|
||||
* 删除数据
|
||||
|
||||
示例3-9 Python删除已存在的MySql数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 删除SQL
|
||||
deleteResult = cursor.execute('DELETE From mysql_study where name="python"')
|
||||
print("删除数据的结果 : %s " % deleteResult)
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
上面的示例3-9演示了删除数据的操作流程,由于SQL语句中给定的Where子句为 name = "python",但是上面的示例我们已经将该条数据的name修改为blockchain,所有deleteResult会返回0。修改where子句为name="blockchain",重新执行后会看到返回结果为1,说明执行成功,删除了一条数据。
|
||||
|
||||
### 3.1.3 通过Python查询MySql数据
|
||||
使用pymsql执行查询操作,同样也是借助于cursor调用fetchXXX()方法来实现。
|
||||
|
||||
* 查询数据
|
||||
|
||||
示例3-10 Python查询MySql的数据
|
||||
```
|
||||
import pymysql
|
||||
# 打开数据库连接
|
||||
db = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
# 使用 cursor() 方法创建一个游标对象 cursor
|
||||
cursor = db.cursor()
|
||||
# 使用 execute() 方法执行 查询SQL
|
||||
cursor.execute('SELECT * FROM mysql_study')
|
||||
# 通过游标获取所有查询到的数据
|
||||
result = cursor.fetchone()
|
||||
while result != None:
|
||||
print(result, cursor.rownumber)
|
||||
result = cursor.fetchone()
|
||||
|
||||
# 提交sql
|
||||
db.commit()
|
||||
# 关闭数据库连接
|
||||
db.close()
|
||||
```
|
||||
|
||||
上面的示例3-10演示了查询指定表中的所有数据的方法,通过传入的Sql语句,也可以为查询增加where查询字句筛选数据。
|
||||
|
||||
pymysql的cursor查询,提供了3种方法获取查询到的数据:
|
||||
1. fetchone() 获取一条数据
|
||||
2. fetchall() 获取所有查询到的数据
|
||||
3. fetchmany(count) 获取指定条数的数据
|
||||
|
||||
开发者可以根据实际情况调用不同的接口,例如当数据量不大时,可以直接通过fetchall()方法获取到所有的数据,然后再遍历结果即可。如果数据量不大,可以通过fetchmany()方法获取游标后指定个数的数据,当然也可以像上面的例子那样,使用fetchone()查询一条数据。
|
||||
|
||||
另外cursor还提供了scroll()方法,顾名思义,这个方法是让cursor跳过指定条目的数据,这样结合fetchmany()就可以轻松获取到需要翻页显示的数据。
|
||||
## 3.2 Python与非关系型数据库
|
||||
非关系型数据库是相对于传统的关系型数据而言的,意指数据库中的数据相互之间不存在关系,其最常见的解释是“non-relational”(非关系),不过另外一种解释“Not Only SQL”(不仅是结构化查询语言)也被很多人接受。非关系型数据库的主要优点有:易扩展、大数据量、高性能。这些特性非常适合高速发展的互联网行业,目前应用比较广泛的非关系型数据库主要有Redis、MongoDb、HBase等,接下来我们学习如何使用Python来操作MongoDB和Redis数据库。
|
||||
### 3.2.1 Python与MongoDB开发环境准备
|
||||
MongoDB 是一个由C++编写的,基于分布式文件存储的开源数据库系统。它的特点是高性能、易部署、易使用,存储数据方便。类似于关系型数据库中一条数据是以行的形式存在,MongoDB中的每条数据是以文档的形式存在,多个文档组合成为一个文档集合,多个文档集合又组成了MongoDB中的一个数据库。因此当我们需要访问指定的数据时,一般需要通过指定对应的数据库-数据集-文档的方式获取数据。
|
||||
|
||||
* 安装MongoDB数据库
|
||||
|
||||
|
||||
你可以在MongoDB官网的下载中心(https://www.mongodb.com/try/download/community),下载编译好的安装文件。
|
||||
打开安装文件,按照提示安装即可。
|
||||
|
||||
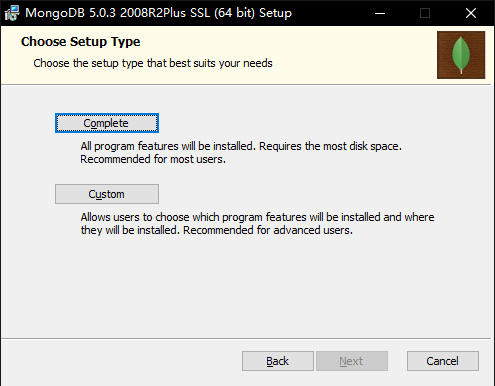
选择完全安装。
|
||||
|
||||
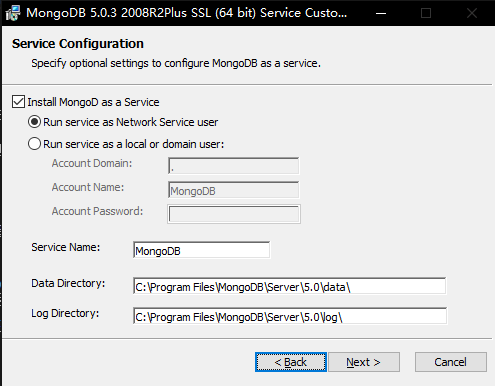
设置MongoDB的服务名、数据目录和Log保存目录,选择下一步,点击【install】安装,等待安装完成。
|
||||
|
||||
* 启动MongoDB数据库
|
||||
打开命令行工具界面,使用命令行启动MongoDB服务
|
||||
```
|
||||
# 进入MongoDB的安装目录,默认为C:\Program Files\MongoDB\Server\5.0\bin
|
||||
cd C:\Program Files\MongoDB\Server\5.0\bin
|
||||
# 启动MOngoDB服务
|
||||
mongod
|
||||
```
|
||||
|
||||
* 简单使用MongoDB客户端
|
||||
服务启动后,默认使用安装时设置的数据库文件路径。接下来可以继续在当前的命令行窗口中连接MongoDB服务:
|
||||
```
|
||||
mongo.exe
|
||||
```
|
||||
|
||||
或双击运行该运行文件,即可进入到Mongo自带的Shell交互环境,连接到本机的MongoDB服务。默认情况下,Mongo Shell会自动连接到test数据库,在Mongo Shell环境下,当一行以大于号开头,说明是用户输入的命令,输入db命令查看当前使用的数据库名称:
|
||||
```
|
||||
> db
|
||||
test
|
||||
```
|
||||
|
||||
MongoDB中的数据是以类似Json的格式来存储的,我们可以通过下面的命令向数据库中插入一条数据:
|
||||
```
|
||||
# 向数据库中插入一条文档数据
|
||||
> db.test.insert({"name":"blockChain"})
|
||||
WriteResult({ "nInserted" : 1 })
|
||||
```
|
||||
上面的示例中,db.test.insert({"name":"blockChain"}) 语句说明我们要向test数据库中插入一条数据{"name":"blockChain"},执行后的结果提示我们此次操作成功插入一条数据。
|
||||
|
||||
接下来我们将插入的数据查询出来:
|
||||
```
|
||||
# 查询数据库中的数据
|
||||
> db.test.find()
|
||||
{ "_id" : ObjectId("61715a409f81ba968524e0da"), "name" : "blockChain" }
|
||||
```
|
||||
通过db.test.find()方法,我们可以查询到所有test内的数据,可以看到,MongoDB自动为我们插入的数据赋值了一个id。
|
||||
|
||||
向当前数据库插入一个数据集。
|
||||
```
|
||||
# 创建一个数据集
|
||||
> db.createCollection("myCollection")
|
||||
{ "ok" : 1 }
|
||||
```
|
||||
|
||||
查询当前数据库中的所有数据集
|
||||
```
|
||||
> show collections
|
||||
myCollection
|
||||
test
|
||||
```
|
||||
|
||||
查询数据集中的文档数据
|
||||
```
|
||||
> db.test.find()
|
||||
{ "_id" : ObjectId("61715a409f81ba968524e0da"), "name" : "blockChain" }
|
||||
> db.myCollection.find()
|
||||
```
|
||||
上面的示例中可以看到,我们此前插入的文档数据默认被写入到test数据集中,而查询myCollection数据集,返回的结果为空。
|
||||
|
||||
### 3.2.2 通过Python操作MongoDB数据库
|
||||
与上面操作MySql类似,通过Python操作MongoDB,也需要先下载MongoDB数据库的连接组件。仍然在命令行工具界面使用pip执行下面的命令:
|
||||
```
|
||||
pip install pymongo
|
||||
```
|
||||
|
||||
* 使用Python连接MongoDB数据库
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取所有的MongoDB数据库
|
||||
dbNameList = mongoClient.list_database_names()
|
||||
# 遍历打印所有的数据库名称
|
||||
for dbName in dbNameList:
|
||||
print(dbName)
|
||||
```
|
||||
上面的例子中,我们使用pymongo连接本地MongoDB服务后,打印出了服务中所有的数据库名称。
|
||||
|
||||
|
||||
* 使用Python创建数据集
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
db.create_collection("testCollection")
|
||||
# 查询数据集
|
||||
for collection in db.list_collections():
|
||||
print(collection)
|
||||
```
|
||||
上面的示例中,演示了连接本地的MongoDB数据库服务,在名为testDB的数据库中创建了testCollection数据集,之后通过db.list_collections()方法获取到指定数据库中的所有数据集,将数据集打印了出来。
|
||||
|
||||
* 使用Python向MongoDB写入文档数据
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 插入一条数据
|
||||
collection.insert_one({"name":"dataTest1", "value": "dataValue1-edit"})
|
||||
# 插入多条数据
|
||||
collection.insert_many([{"name":"dataTest2", "value": "dataValue2"}, {"name":"dataTest3", "value": "dataValue3"}])
|
||||
|
||||
# 查询数据集中的数据
|
||||
for data in collection.find():
|
||||
print(data)
|
||||
```
|
||||
上面的示例演示了使用pymongo向MongoDB数据库中写入数据的方法,pymongo提供了insert_one和insert_many两种插入数据的方法,分别为插入一条数据或多条数据。
|
||||
|
||||
* 使用Python查询MongoDB中的文档数据
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 查询一条数据
|
||||
listData = collection.find()
|
||||
print("查询所有数据的结果:")
|
||||
for data in listData:
|
||||
print(data)
|
||||
|
||||
# 查询name是dataTest2的数据
|
||||
dataTest1 = collection.find({"name": "dataTest2"})
|
||||
print("查询 name = dataTest2的结果:")
|
||||
for data in dataTest1:
|
||||
print(data)
|
||||
```
|
||||
上面的示例演示了使用pymongo查询数据的方法,在数据集对象上调用find()方法即可查询该数据集中的所有数据,如果想要根据条件查询,可以参考下表的表达式查询给定条件的数据。
|
||||
|
||||
|
||||
* 使用Python更新MongoDB中的文档数据
|
||||
```
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 更新一条数据,name是dataTest2的数据,修改name的值为dataTest-edit
|
||||
collection.update_one(
|
||||
{'name':'dataTest2'},
|
||||
{'$set':{
|
||||
'name': 'dataTest2-edit'
|
||||
}
|
||||
}
|
||||
)
|
||||
# 更新多条数据,value都被修改为value-edit,新增了一个键值对'anotherValue': 'test'
|
||||
collection.update_many(
|
||||
{},
|
||||
{'$set':{
|
||||
'value': 'value-edit',
|
||||
'anotherValue': 'test'
|
||||
}
|
||||
}
|
||||
)
|
||||
# 查询所有数据
|
||||
dataTest1 = collection.find({})
|
||||
print("查询 name = dataTest2的结果:")
|
||||
for data in dataTest1:
|
||||
print(data)
|
||||
```
|
||||
|
||||
* 使用Python删除MongoDB中的文档数据
|
||||
```python
|
||||
import pymongo
|
||||
# 连接MongoDB数据库
|
||||
mongoClient = pymongo.MongoClient("mongodb://localhost:27017/")
|
||||
# 获取mongoTest数据库,如果不存在,则自动创建
|
||||
db = mongoClient.get_database("testDB")
|
||||
# 获取数据集,如果不存在,则自动创建
|
||||
collection = db.get_collection("testCollection")
|
||||
if collection == None:
|
||||
collection = db.create_collection("testCollection")
|
||||
# 删除一条数据,删除name的值为dataTest-edit的数据
|
||||
deleteOneResult = collection.delete_one({
|
||||
'name': 'dataTest2-edit'
|
||||
})
|
||||
print("删除一个数据的结果:"+ str(deleteOneResult.raw_result))
|
||||
|
||||
# 删除多条数据,删除name是dataTest开头的所有数据
|
||||
deleteManyResult = collection.delete_many(
|
||||
{
|
||||
'name': {'$regex': 'dataTest'}
|
||||
}
|
||||
)
|
||||
|
||||
print("删除多个数据的结果:"+ str(deleteManyResult.raw_result))
|
||||
|
||||
# 查询name是dataTest2的数据
|
||||
dataTest1 = collection.find({})
|
||||
print("查询 name = dataTest2的结果:")
|
||||
for data in dataTest1:
|
||||
print(data)
|
||||
```
|
||||
|
||||
### 3.2.3 Python与Redis开发环境准备
|
||||
|
||||
Redis是一个开源的、遵守 BSD 开源协议,是一个高性能的 key-value 数据库。它支持数据的持久化,它不仅支持简单数据类型的保存,还对list、set等复杂数据类型也有很好的支持。
|
||||
Redis有着极高的读写效率,读取速率可达110000次/秒,写入速率也有高达80000次/秒,因此Redis数据库也常被用来作为程序中缓存数据的读写方案。
|
||||
|
||||
* 安装Redis
|
||||
你可以在Redis github的Release页面(https://github.com/tporadowski/redis/releases)下载最新的安装程序。
|
||||
|
||||
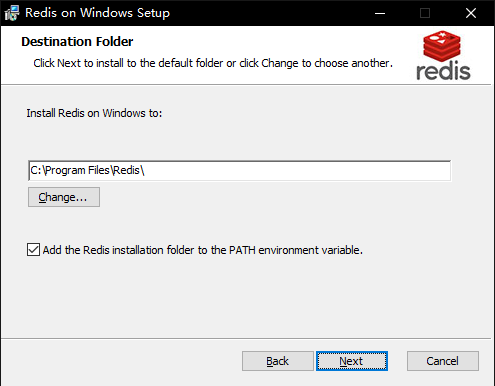
打开安装程序,按照提示安装程序
|
||||
|
||||
可修改Redis的安装目录,以及将Redis的安装目录添加到环境变量path中。
|
||||
|
||||
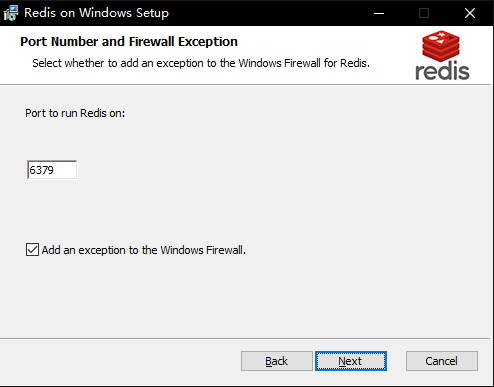
Redis的默认端口号为6379。
|
||||
|
||||
* 简单使用Redis
|
||||
打开命令行工具界面,进入到redis的安装目录,启动Redis服务,保持该界面为打开状态
|
||||
```
|
||||
# 进入Redis的安装路径中
|
||||
cd C:\Program Files\Redis
|
||||
|
||||
# 启动Redis服务
|
||||
redis-server.exe redis.windows.conf
|
||||
```
|
||||
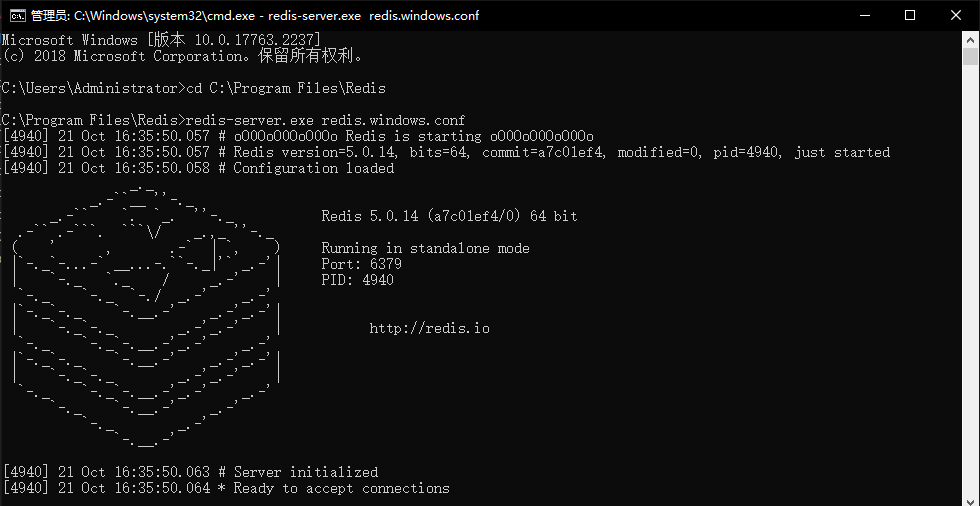
如下图所示,说明Redis服务已经启动成功,保持该界面为打开状态。
|
||||
|
||||
|
||||
重新打开一个命令行工具界面,进入Redis安装目录后,使用Redis新增、查询数据。
|
||||
```
|
||||
# 进入Redis的安装路径中
|
||||
cd C:\Program Files\Redis
|
||||
|
||||
# 进入redis客户端命令行模式
|
||||
redis-cli
|
||||
|
||||
# 向Redis中存储数据:myKey-myValue
|
||||
127.0.0.1:6379> set myKey myValue
|
||||
# 存储成功
|
||||
OK
|
||||
# 获取myKey对应的值
|
||||
127.0.0.1:6379> get myKey
|
||||
# 获取成功
|
||||
"myValue"
|
||||
```
|
||||
### 3.2.4 通过Python操作Redis数据库
|
||||
与上述章节类似,接下来我们学习使用Python代码操作Redis数据库。
|
||||
|
||||
在命令行工具中,执行以下语句,下载Redis的连接组件。
|
||||
```
|
||||
pip install redis
|
||||
```
|
||||
|
||||
* 使用Python向Redis数据库中写入数据
|
||||
```
|
||||
import redis
|
||||
# 连接Redis数据库,host为Redis服务地址,port为Redis服务端口,encoding为编码格式,db为连接的数据库名称-默认名称为0
|
||||
conn = redis.Redis(host='localhost', port='6379', encoding='utf-8', db=0)
|
||||
# 写入值
|
||||
# 其他参数说明
|
||||
# nx-如果设置为True,则只有key不存在时,当前set操作才执行,同#setnx(key, value)
|
||||
# xx-如果设置为True,则只有key存在时,当前set操作才执行,同setxx(key, value)
|
||||
# ex-过期时间(秒)
|
||||
# px-过期时间(毫秒)
|
||||
conn.set("blockChain", "good")
|
||||
# 写入值,当key不存在时才执行
|
||||
conn.set("blockChain", "very good", nx=True)
|
||||
# 批量设置值
|
||||
conn.mset({"mkey1":'mvalue1', "mkey2":'mvalue2'})
|
||||
```
|
||||
上面的例子中,我们在连接redis数据库后,通过set(key, value)方法向redis中写入数据。程序也支持批量写入数据,可以很方便地将Python的Dict数据按照k-v的格式存储到Redis数据库中。
|
||||
|
||||
由于Redis是k-v数据库,对数据库的更新与插入,操作流程几乎相同,根据指定的key是否存在而是否执行写入操作,就可以控制数据库的更新与插入是否执行。
|
||||
|
||||
上面的例子中,我们对blockChain执行了两次写入操作,第二次增加了nx=True的参数,读者朋友可以测试一下,程序执行结束后,blockChain对应的值是什么?
|
||||
|
||||
* 使用Redis查询数据
|
||||
```
|
||||
import redis
|
||||
# 连接Redis数据库,host为Redis服务地址,port为Redis服务端口,encoding为编码格式,db为连接的数据库名称-默认名称为0
|
||||
conn = redis.Redis(host='localhost', port='6379', encoding='utf-8', db=0)
|
||||
# 读取值
|
||||
print("blockChain的值是:", conn.get("blockChain"))
|
||||
# 批量读取值
|
||||
mValues = conn.mget(("mkey1", "mkey2"))
|
||||
for value in mValues:
|
||||
print(value)
|
||||
```
|
||||
|
||||
上述示例演示了使用Python读取Redis数据库内数据的方法,同写入数据类似,也支持单个读取get(key)和批量读取mget((key1, key2...))数据,开发者可以轻松使用这些接口实现对Redis数据库的读取操作。
|
||||
## 疑难解答
|
||||
### 1. 为什么一定要使用数据库?
|
||||
我们知道,程序是运行在计算机的内存中的,当程序退出或计算机关闭后,程序执行的结果也就随之消失了。但是实际业务中经常需要让程序在下一次运行时仍然可以获取到上一次的执行结果,这个时候我们就需要将运行的结果“持久化”保存起来,这就是所谓的“持久化”。
|
||||
|
||||
例如一个学生信息管理系统,需要记录每个学生的学号、姓名以及各科成绩,每次考试都需要记录学生的考试成绩。程序不可能在几年的时间中一直保持运行,就需要将这些信息保存到硬盘中。如果这个系统中维护的数据仅仅是一个班的几十名同学的数据,那么使用文本文件来保存也未尝不可,但是当程序要维护的学生数据是整个省的数十万的学生数据,使用这样的方式就会极为不方便,由于各个学校考试时间不同,很多时候只是要更新某一个学校学生的数据,这个时候就需要被保存的数据还可以支持方便的查询、修改、删除的操作,而这些功能,就是一个数据库管理系统最擅长的领域,这也是程序必须使用数据库的原因。
|
||||
### 2. 关系型数据库和非关系型数据库的差异?
|
||||
关系型数据库中保存的都是以结构化数据为主,每个结构化数据组成一张表,各个表之间通过主键、外键相互关联。结构化数据库的优点是符合大多数的业务认知,维护起来相对简单,使用也十分方便,缺点就是读写效率较慢,表结构因为相互关联,灵活度相对不足。这些缺点恰好就是高速发展的互联网行业的最大痛点,多数互联网行业业务都是高速发展的,需要频繁地更新表结构,而且因为面对个人群体,用户量也极为庞大,这些特点注定了他们需要一种不仅仅可以完美支持可以支持高并发、大数据量并且可以灵活变更数据结构的数据库,这也就诞生了“No SQL”——非关系型数据库。
|
||||
|
||||
非关系型数据库弥补了关系型数据库的缺点,但是学习和使用成本则相对较高,除此之外,非关系型数据库没有对事务的支持,同时相比于关系型数据库,查询方式也较为简单。可以说,两种数据库互有优劣,使用时根据各自的业务需要,选择适合自己的数据库即可。
|
||||
|
||||
## 实训:抓取视频和新闻网站的数据
|
||||
这里我们以抓取登链社区(https://learnblockchain.cn/)的精选文章为例,演示如何使用Python抓取网站数据并将抓取到的数据保存在数据库中。登链社区是一群区块链技术爱好者共同维护的社区,也是国内区块链较为知名的社区之一。网站开放以来累计服务了超过百万的读者,社区以高质量的内容得到广大读者的好评。
|
||||
|
||||
以下图为例,进入到登链社区的精选文章页面,通过切换页码,会发现分页链接以较为规律的形式形成,通过参数page来设置当前所处的页数,下面以抓取精选文章前20页的文章内容为例。
|
||||
|
||||
抓取文章数据,需要依靠下面的几个开放组件完成,下面主要介绍一下各个组件在抓取数据流程中的作用。
|
||||
url包:提供了request工具获取指定url对应的html源码,通过html源码来获取需要抓取的信息。
|
||||
bs4包:提供了BeautifulSoap工具,可以方便地从html源码中解析需要的数据。
|
||||
|
||||
```
|
||||
# -*- codeing = utf-8 -*-
|
||||
from bs4 import BeautifulSoup # 网页解析,获取数据
|
||||
import urllib.request, urllib.error # 制定URL,获取网页数据
|
||||
import pymysql # mysql数据库
|
||||
|
||||
mysqlDB = pymysql.connect(host="localhost", port=3306, user="root", password="******", database="test")
|
||||
cursor = mysqlDB.cursor()
|
||||
|
||||
# 定义抓取页面的主方法
|
||||
# startPage为抓取的其实页, endPage为抓取的结束页
|
||||
def main(startPage, endPage):
|
||||
# 定义抓取的起始页
|
||||
startUrl = "https://learnblockchain.cn/categories/all/featured?page={num}"
|
||||
for page in range(startPage, endPage+1):
|
||||
# 获取到指定url的html源码
|
||||
html = getUrlHtml(startUrl.replace("{num}", str(page)))
|
||||
# 调用Jsoup对html源码解析,获取需要的标题内容数据
|
||||
titleBlockList = getTitleBlock(html)
|
||||
# 使用正则表达式解析标题代码块内的内容,并且将数据保存在对象中
|
||||
for item in titleBlockList:
|
||||
# 使用dict记录需要被保存的数据
|
||||
dataDict = {}
|
||||
# 获取h2标签内容,从中解析标题内容及链接
|
||||
titleSoup = BeautifulSoup(str(item), "html5lib")
|
||||
|
||||
# 在代码块中获取h2的标签,即为标题标签,可以获取到标题的文本内容和链接
|
||||
titleTag = titleSoup.find(name="h2", class_="title")
|
||||
# 获取titleTag中的超链接a标签,获取链接地址和标题文本
|
||||
title = titleTag.find(name="a")
|
||||
dataDict["title"] = title.string
|
||||
dataDict["href"] = title["href"]
|
||||
|
||||
# 从item里获取标题中的描述性文字
|
||||
descriptionTag = titleSoup.find(name="p")
|
||||
if descriptionTag != None:
|
||||
dataDict["description"] = descriptionTag.string
|
||||
|
||||
# 从item里获取作者信息
|
||||
authorTag = titleSoup.find(name="ul", class_="author")
|
||||
if authorTag!=None:
|
||||
dataDict["author"] = authorTag.find(name="a").text
|
||||
|
||||
# 将map数据保存到mysql数据库中
|
||||
saveIntoMySql(dataDict)
|
||||
|
||||
|
||||
# 得到指定一个URL的网页内容
|
||||
def getUrlHtml(url):
|
||||
request = urllib.request.Request(url)
|
||||
html = ""
|
||||
try:
|
||||
response = urllib.request.urlopen(request)
|
||||
html = response.read().decode("utf-8")
|
||||
except urllib.error.URLError as e:
|
||||
if hasattr(e, "code"):
|
||||
print(e.code)
|
||||
if hasattr(e, "reason"):
|
||||
print(e.reason)
|
||||
return html
|
||||
|
||||
# 获取标题列表页面中所有的标题代码块
|
||||
def getTitleBlock(html):
|
||||
beautifulSoup = BeautifulSoup(html, features="html.parser")
|
||||
# 定义一个数组,保存所有的标题内容
|
||||
resultSet = beautifulSoup.find_all('section', class_="stream-list-item") # 查找符合要求的字符串
|
||||
return resultSet
|
||||
|
||||
# 将数据保存到MySql数据库中
|
||||
def saveIntoMySql(dataDict):
|
||||
# 定义插入数据库的语句
|
||||
sqlstr = '''INSERT INTO test.learnblockchain
|
||||
(title, href, description, author)
|
||||
VALUES
|
||||
("{title}", "{href}", "{description}", "{author}")
|
||||
'''
|
||||
# 格式化sql语句,将数据内容替换到sql语句中
|
||||
try:
|
||||
sqlstr = sqlstr.format(title=dataDict['title'].strip(), href=dataDict['href'].strip(), description=dataDict['description'].strip(), author=dataDict['author'].strip())
|
||||
result = cursor.execute(sqlstr)
|
||||
mysqlDB.commit()
|
||||
# 执行插入操作
|
||||
print("插入结果:", result)
|
||||
except BaseException as e:
|
||||
print(e)
|
||||
|
||||
# 初始化MySql数据库,建表
|
||||
def initMySql():
|
||||
# 打开数据库连接
|
||||
createTableResult = cursor.execute('''
|
||||
CREATE TABLE IF NOT EXISTS test.learnblockchain(`id` INT AUTO_INCREMENT ,
|
||||
`title` VARCHAR(300) NOT NULL,
|
||||
`href` VARCHAR(300) NOT NULL,
|
||||
`description` VARCHAR(300) NOT NULL,
|
||||
`author` VARCHAR(50) NOT NULL,
|
||||
PRIMARY KEY (`id`))
|
||||
default charset = utf8;
|
||||
''')
|
||||
mysqlDB.commit()
|
||||
return createTableResult,mysqlDB
|
||||
|
||||
if __name__ == "__main__": # 当程序执行时
|
||||
initMySql()
|
||||
# 调用函数
|
||||
main(1, 2)
|
||||
print("数据抓取完毕!")
|
||||
if mysqlDB != None:
|
||||
mysqlDB.close()
|
||||
```
|
||||
上面的示例中仅仅抓取了网站内的精选文章板块,并且只抓取了文章列表的标题、文章访问地址、内容简介以及作者,并且将抓取的数据保存在MySql数据库中。有兴趣的读者可以在此基础上尝试修改示例,根据文章访问地址获取到文章的全部文本内容,然后将抓取到的数据保存在MongoDB数据库中。
|
||||
|
||||
## 本章总结
|
||||
本章主要介绍了使用Python对MySql、MongoDB和Redis等数据库做一些简单的增删改查操作,数据库可以说是一个应用程序的基础,因为程序本质就是处理数据的输入输出以及对数据做必要的逻辑处理,而Python对各种数据库的支持也堪称全面,使用pysql基本可以满足绝大多数的业务需求。
|
||||
BIN
language/Python区块链/Python与数据库.odt
Normal file
BIN
language/Python区块链/Python与数据库.odt
Normal file
Binary file not shown.
3
language/Python区块链/Python基础篇.md
Normal file
3
language/Python区块链/Python基础篇.md
Normal file
@@ -0,0 +1,3 @@
|
||||
区块链(blockchain)是借由密码学串接并保护内容的串连文字记录(又称区块),而数字货币则是区块链目前最大的应用方向。
|
||||
|
||||
区块链可以通过不同的编程语言来实现,
|
||||
33
language/Python区块链/Python的语法特色.md
Normal file
33
language/Python区块链/Python的语法特色.md
Normal file
@@ -0,0 +1,33 @@
|
||||
# 第2章 Python的语法特色
|
||||
## 2.1 Python的数据处理工具
|
||||
### 2.1.1 迭代器
|
||||
### 2.1.2 切片
|
||||
### 2.1.3 数据生成器
|
||||
### 2.1.4 lambda表达式
|
||||
## 2.2 模块与包
|
||||
### 2.2.1 第三方模块的安装与使用
|
||||
### 2.2.2 Numpy
|
||||
### 2.2.3 ~
|
||||
### 2.2.4 shapely
|
||||
## 2.3 并发编程~
|
||||
### 2.3.1 并发编程思想
|
||||
### 2.3.2 多进程编程
|
||||
### 2.3.4 多线程编程
|
||||
## 2.4 正则表达式
|
||||
### 2.4.1 正则表达式的基本规则
|
||||
### 2.4.2 在Python中处理正则表达式
|
||||
## 2.5 标准库的使用
|
||||
### 2.5.1 map简介
|
||||
### 2.5.2 raduce简介
|
||||
### 2.5.3 sorted简介
|
||||
### 2.5.3 filter简介
|
||||
## 2.6 网络编程
|
||||
### 2.6.1 TCP协议简介
|
||||
### 2.6.2 如何搭建TCP服务器
|
||||
### 2.6.3 HTTP协议简介
|
||||
### 2.6.4 如何搭建Web服务器
|
||||
## 疑难解答
|
||||
### 1. 为什么多数网站都是基于http协议搭建的
|
||||
### 2. 进程与线程的区别
|
||||
## 实训:Python实现简单的http服务器
|
||||
## 本章总结
|
||||
1479
language/Python区块链/Python语法基础-1014-001.md
Normal file
1479
language/Python区块链/Python语法基础-1014-001.md
Normal file
File diff suppressed because it is too large
Load Diff
1490
language/Python区块链/Python语法基础-1015-001.md
Normal file
1490
language/Python区块链/Python语法基础-1015-001.md
Normal file
File diff suppressed because it is too large
Load Diff
1484
language/Python区块链/Python语法基础-all.md
Normal file
1484
language/Python区块链/Python语法基础-all.md
Normal file
File diff suppressed because it is too large
Load Diff
855
language/Python区块链/Python语法基础-辛.md
Normal file
855
language/Python区块链/Python语法基础-辛.md
Normal file
@@ -0,0 +1,855 @@
|
||||
### 1.2.1 基础数据类型
|
||||
|
||||
Python 3 为了便于大家编写程序,支持多种数据类型。主要由六类标准的数据类型构成,它们分别是:Number(数字)、String(字符串)、List(列表)、Tuple(元组)、Set(集合)、Dictionary(字典)。
|
||||
|
||||
Python语言通过对多个数据元素进行组合,为开发者们提供了几个非常有特色的复合数据类型。List、Tuple、Set、Dictionary都是非常典型的复合数据类型。String本质上也是一种复合数据类型,字符串中的每个字符都被视为一个数据元素。
|
||||
|
||||
- Number (数字)
|
||||
|
||||
|
||||
数字在编程过程中是最基本的类型。python 3 支持两种典型的数字类型:整数和浮点数。
|
||||
|
||||
整数的数据类型表示为 int,例如:1、3、50、100,都是比较典型的整数。通常情况下我们定义一个整数,默认是十进制的整数。python 3 在此基础上还支持2进制整数、8进制整数和16进制整数。
|
||||
|
||||
浮点数表示含有小数部分的数字,类型表示为float。例如:3.14、333.333、4.0,都是比较典型的浮点数。在python 3 中允许开发者们使用科学计数法表示浮点数,写法也非常的简单,两个数字中间夹杂一个字母 e,不区分大小写,e或E都可以。例如:5e3、6E4。其中字母e后边的数字表示10的幂次,换算后,乘以前面的数字得到实际数字。
|
||||
$$
|
||||
5e3 表示 5*10^3。
|
||||
$$
|
||||
|
||||
```python
|
||||
>>> i = 5e3
|
||||
>>> print(i1)
|
||||
5000.0
|
||||
>>> j = 3E-3
|
||||
>>> print(j)
|
||||
0.003
|
||||
```
|
||||
|
||||
- String(字符串)
|
||||
|
||||
|
||||
除了数字,Python支持的另一种常见数据类型为字符串,在程序中定义一个字符串类型的数据是非常容易的。使用单引号(')或双引号(")将内容圈起来,引号内的内容即为字符串本身。Python没有单独定义字符类型,一个字符就是一个只有一个字符的字符串。
|
||||
|
||||
```python
|
||||
>>> str1 = '床前明月光'
|
||||
>>> print(str1)
|
||||
床前明月光
|
||||
>>> str2 = "疑是地上霜"
|
||||
>>> print(str2)
|
||||
疑是地上霜
|
||||
```
|
||||
|
||||
那么如果在字符串中出现单引号或双引号该怎么办?python提供了\来对其中的引号进行转义。避免和用于定义字符串所使用的引号混淆。
|
||||
|
||||
```python
|
||||
>>> str3 = '床前\'明月\'光'
|
||||
>>> print(str3)
|
||||
床前'明月'光
|
||||
```
|
||||
|
||||
如果我们要表达的字符串内容是多行的,可以采用三个单引号 ''' 或三个双引号 """ 将多行内容圈起来。当然也可以使用特定字符 \r\n 来实现换行效果。
|
||||
|
||||
```python
|
||||
>>> str4 = '''床前明月光
|
||||
疑是地上霜
|
||||
举头望明月
|
||||
低头思故乡'''
|
||||
>>> print(str4)
|
||||
床前明月光
|
||||
疑是地上霜
|
||||
举头望明月
|
||||
低头思故乡
|
||||
>>> str5 = """床前明月光
|
||||
疑是地上霜
|
||||
举头望明月
|
||||
低头思故乡"""
|
||||
>>> print(str5)
|
||||
床前明月光
|
||||
疑是地上霜
|
||||
举头望明月
|
||||
低头思故乡
|
||||
>>> str6 = '床前明月光\r\n疑是地上霜\r\n举头望明月\r\n低头思故乡'
|
||||
>>> print(str6)
|
||||
床前明月光
|
||||
疑是地上霜
|
||||
举头望明月
|
||||
低头思故乡
|
||||
```
|
||||
|
||||
### 1.2.2 学会使用list和tuple
|
||||
|
||||
List(列表)和Tuple(元组)是非常常用的复合数据类型,它们都是将多个数据元素有序的集合在一起。
|
||||
|
||||
- List(列表)
|
||||
|
||||
|
||||
List(列表)是 python 提供的一种复合数据类型,它将多个数据元素集合起来并用逗号分隔,再由方括号括起来。例如:List1 = [ ’A’ , ’B’ , ’C’ ] 。python中并没有对List中的数据元素的数据类型做约束,所以一个 List 中的不同数据元素可以是不同的数据类型。
|
||||
|
||||
List是一种有序的集合。可以通过索引的方式,访问List指定位置的数据元素。其中第一个数据元素的索引值为0,即从0开始计数。另外索引还支持反向查找元素,-1表示最后一个元素,以此类推-2表示取倒数第二个元素。
|
||||
|
||||
以List1 = [ ’A’ , ’B’ , ’C’ ] 为例:
|
||||
|
||||
| 元素 | ’A’ | ’B’ | ’C’ |
|
||||
| -------- | :---------- | ----------- | ----------- |
|
||||
| 正向索引 | List1[ 0 ] | List1[ 1 ] | List1[ 2 ] |
|
||||
| 反向索引 | List1[ -3 ] | List1[ -2 ] | List1[ -1 ] |
|
||||
|
||||
List支持基本的增加、删除、修改操作,以List1 = ['A', 'B', 'C'] 、List2 = [ 'P', 'Q'] 为例:
|
||||
|
||||
| 操作 | 命令 | 结果 | 说明 |
|
||||
| :--- | ------------------------ | ------------------------------ | -------------------- |
|
||||
| 增加 | List1.append( 'D' ) | ['A' , 'B' , 'C' , 'D' ] | 末尾添加单个元素 |
|
||||
| 增加 | List1.extend( List2 ) | ['A' , 'B' , 'C' , 'P' , 'Q' ] | 末尾添加多个元素 |
|
||||
| 增加 | List1.insert( 1 , 'P' ) | ['A' , 'P' , 'B' , 'C' ] | 指定位置添加元素 |
|
||||
| 删除 | List1.pop() | ['A' , 'B' ] | 删除末尾元素 |
|
||||
| 删除 | List1.pop(1) | ['A' , 'C' ] | 删除指定位置元素 |
|
||||
| 删除 | del List1[1] | ['A' , 'C' ] | 删除指定位置元素 |
|
||||
| 删除 | del List1[1:] | ['A' ] | 删除指定范围内的元素 |
|
||||
| 删除 | List1.remove('C') | ['A' , 'B' ] | 删除第一次匹配的元素 |
|
||||
| 修改 | List1[1]=’K’ | ['A' , 'K' , 'C' ] | 赋值修改指定位置元素 |
|
||||
|
||||
可以通过python 3 的内置函数len()获得当前List中的元素个数。
|
||||
|
||||
```python
|
||||
>>> List3 = [ 1 , 2 , 3 ]
|
||||
>>> len(List3)
|
||||
3
|
||||
>>> List4 = [ 'A' , 1 , True ]
|
||||
>>> len(List4)
|
||||
3
|
||||
```
|
||||
|
||||
List自身的成员函数count()统计某个元素在List中出现的次数。例如List5 = [ 1 , 2 , 3 , 1 , 3 ]中的元素1出现了两次,通过调用count(),我们可以看到返回的结果也是2。
|
||||
|
||||
```python
|
||||
>>> List5 = [ 1 , 2 , 3 , 1 , 3 ]
|
||||
>>> List5.count(1)
|
||||
2
|
||||
>>> List5.count(2)
|
||||
1
|
||||
```
|
||||
|
||||
如上,我们知道List5 = [ 1 , 2 , 3 , 1 , 3 ]中的元素1出现了两次,那么如何找到它第一次出现时的索引值呢?List提供了index()函数用于确定某个元素在List中第一次出现时的位置。例如List5中的元素3,第一次出现的索引值为2。而List5中的元素1,第一次出现的索引值为0。
|
||||
|
||||
```python
|
||||
>>> List5 = [ 1 , 2 , 3 , 1 , 3 ]
|
||||
>>> List5.index(3)
|
||||
2
|
||||
>>> List5.index(1)
|
||||
0
|
||||
```
|
||||
|
||||
为了使代码编写更简洁,List还支持+运算符。+实现多个List的顺序拼接。
|
||||
|
||||
例如:已知两个列表List6 = [ 1 , 2 ]和List7 = [ 3 , 4 ],现在想把它们的要素合并成到一起生成一个新的序列[1 , 2 , 3 , 4 ],该序列中List6、List7各自元素内部顺序保持不变,且List6的元素排在List7前边。
|
||||
|
||||
```python
|
||||
>>> List6 = [ 1 , 2 ]
|
||||
>>> List7 = [ 3 , 4 ]
|
||||
>>> List6 + List7
|
||||
[1, 2, 3, 4]
|
||||
```
|
||||
|
||||
List还支持\*运算符。\*运算符后边追加数字n,实现将List的元素顺序拼接n次。例如将List6 = [ 1 , 2 ]复制三次并顺次拼接到一起可以写为List6*3,即可得到列表[1, 2, 1, 2, 1, 2]。
|
||||
|
||||
```python
|
||||
>>> List6 = [ 1 , 2 ]>>> List6*3[1, 2, 1, 2, 1, 2]
|
||||
```
|
||||
|
||||
- Tuple(元组)
|
||||
|
||||
|
||||
和List(列表)相似,Tuple(元组)同样是一种复合数据类型,而且Tuple也是有序集合。与List最大的不同是Tuple中的元素一旦确定就不能再修改。Tuple的写法和List也十分相似,将多个数据元素集合起来并用逗号分隔,再由方括号括起来。例如:Tuple1 = ( ’A’ , ’B’ , ’C’ )。
|
||||
|
||||
定义只有一个元素的Tuple不能用Tuple1 = (1),此时 () 表示数学公式中的小括号,相当于给变量Tuple1赋值1,而并没有将Tuple1视作Tuple。正确的定义方法应该在第一个元素后边加一个‘,’号,例如:Tuple2 = ( 1, )
|
||||
|
||||
例子中可以看到通过python 3提供的变量数据类型查询方法type()可以看到,通过Tuple1 = (1)赋值。此时Tuple1的数据类型为int,即为整数。而通过Tuple2 = ( 1, )定义的变量Tuple2的数据类型为Tuple。
|
||||
|
||||
```python
|
||||
>>> Tuple1 = (1)>>> type(Tuple1)<class 'int'>>>> Tuple2 = ( 1, )>>> type(Tuple2)<class 'tuple'>
|
||||
```
|
||||
|
||||
实际上,Python在显示只有1个元素的Tuple类型数据时,也会加一个‘,’号避免误会。
|
||||
|
||||
```python
|
||||
>>> print(Tuple2)(1,)
|
||||
```
|
||||
|
||||
### 1.2.3 学会使用dict和set
|
||||
|
||||
Dictionary(字典)和 Set(集合)同样是非常常用的复合数据类型,它们与 List 和 Tuple 最大的不同为内部的元素是无序的。其中 Set(集合)是一组无序元素构成的集合,而Dictionary(字典)是一组无序的键值对构成的集合。
|
||||
|
||||
- Dictionary(字典)
|
||||
|
||||
Dictionary(字典)是一组元素的集合,每一个元素都是键值对(key-value)的形式,元素间用逗号分隔,最后用大括号 {} 将所有元素括起来。 例如:Dict1 = { 'A' : 1 , 'B' : 2 , 'C' : 3 }。其中 'A' : 1 是一个键值对,也是 Dict1 的一个元素,'A' 是该键值对的键(key),1是该键值对的值(value),彼此间用冒号: 分隔。
|
||||
|
||||
Dictionary 中的元素是无序的。所有元素的key值是唯一且不可变的。Number、String 是不可变的,可以作为key。而 List 是可变的,不能作为 key。
|
||||
|
||||
为了便于书写,后边的内容我们把 Dictionary(字典)简写为Dict。
|
||||
|
||||
python 3 同样为 Dict 提供了很多操作,便于开发者们使用。通过 Dict 的 key 值,可以直接获得对应的 value 值,如 Dict1[ 'A' ] 将获得数值 1。
|
||||
|
||||
```python
|
||||
>>> Dict1 = { 'A' : 1 , 'B' : 2 , 'C' : 3 }>>> Dict1['A']1
|
||||
```
|
||||
|
||||
Dict 支持基本的增加、删除、修改操作,以 Dict1 = { 'A' : 1 , 'B' : 2 , 'C' : 3 } 为例:
|
||||
|
||||
| 操作 | 命令 | 结果 | 说明 |
|
||||
| ---- | ---------------- | ----------------------------------------- | ---------------------- |
|
||||
| 增加 | Dict1[ 'D' ] = 4 | { 'A' : 1 , 'B' : 2 , 'C' : 3 , 'D' : 4 } | 添加key-value |
|
||||
| 删除 | Dict1.pop( 'C' ) | { 'A' : 1 , 'B' : 2 } | 删除指定的key及其value |
|
||||
| 删除 | del Dict1[ 'C' ] | { 'A' : 1 , 'B' : 2 } | 删除指定的key及其value |
|
||||
| 修改 | Dict1[ 'C' ] = 4 | { 'A' : 1 , 'B' : 2 , 'C' : 4 } | 修改已有key对应的value |
|
||||
|
||||
判断key在当前Dict中是否存在主要有两种方法:in和get()。
|
||||
|
||||
通过in来判断key是否存在,存在返回True,不存在返回False。
|
||||
|
||||
```python
|
||||
>>> Dict1 = { 'A' : 1 , 'B' : 2 , 'C' : 3 }>>> 'A' in Dict1True>>> 'D' in Dict1False
|
||||
```
|
||||
|
||||
通过内置方法get()来判断key是否存在,存在返回key对应的value,不存在则返回get()函数中预先定义的值,没有预先定义值则返回None。
|
||||
|
||||
```python
|
||||
>>> Dict1 = { 'A' : 1 , 'B' : 2 , 'C' : 3 }>>> Dict1.get('A' , -1)1>>> Dict1.get('D' , -1)-1>>> print(Dict1.get('D'))None
|
||||
```
|
||||
|
||||
如上面的例子所示,'A'是Dict1中的key,且对应的value为1,所以Dict1.get('A' , -1)的返回值为1。'D'不是Dict1中的key,所以Dict1.get('D' , -1)的返回值为预先定义的-1。如果get()方法没有做预先定义,如Dict1.get('D'),则返回值为None。
|
||||
|
||||
实际开发程序时,经常需要将两个Dict合并成一个Dict的情况。python 3 提供了很多种办法。
|
||||
|
||||
以两个Dict为例:
|
||||
|
||||
Dict3 = { 1:[1,11,111] , 2:[2,22,222] }
|
||||
|
||||
Dict4 = { 3:[3,33,333] , 4:[4,44,444] }
|
||||
|
||||
合并后的结果为:
|
||||
|
||||
Dict5 = { 1:[1,11,111] , 2:[2,22,222] , 3:[3,33,333] , 4:[4,44,444] }
|
||||
|
||||
下面为大家介绍三种方法实现Dict的合并。
|
||||
|
||||
方法1:
|
||||
|
||||
Dict的copy()方法可以将Dict中的数据拷贝出来。
|
||||
|
||||
Dict的update()方法实现了对Dict中键值对的更新,不仅可以修改现有key对应的value,还可以添加新的键值对到Dict中。
|
||||
|
||||
```python
|
||||
>>> Dict3 = { 1:[1,11,111] , 2:[2,22,222] }>>> Dict4 = { 3:[3,33,333] , 4:[4,44,444] }>>> Dict5=Dict3.copy()>>> Dict5.update( Dict4 )>>> Dict5{1: [1, 11, 111], 2: [2, 22, 222], 3: [3, 33, 333], 4: [4, 44, 444]}
|
||||
```
|
||||
|
||||
方法2:
|
||||
|
||||
构造函数dict()可以直接将一组键值对创建为Dict。
|
||||
|
||||
```python
|
||||
>>> Dict3 = { 1:[1,11,111] , 2:[2,22,222] }>>> Dict4 = { 3:[3,33,333] , 4:[4,44,444] }>>> Dict5 = dict( Dict3 )>>> Dict5.update( Dict4 )>>> Dict5{1: [1, 11, 111], 2: [2, 22, 222], 3: [3, 33, 333], 4: [4, 44, 444]}
|
||||
```
|
||||
|
||||
方法3:
|
||||
|
||||
Dict的items()方法可将键值对提取出来。
|
||||
|
||||
构造函数list()可以直接将一组数据创建为List。
|
||||
|
||||
Dict5 = dict( list( Dict3.items() ) + list( Dict4.items() ) )
|
||||
|
||||
```python
|
||||
>>> Dict3 = { 1:[1,11,111] , 2:[2,22,222] }>>> Dict4 = { 3:[3,33,333] , 4:[4,44,444] }>>> Dict5 = dict( list( Dict3.items() ) + list( Dict4.items() ) )>>> Dict5{1: [1, 11, 111], 2: [2, 22, 222], 3: [3, 33, 333], 4: [4, 44, 444]}
|
||||
```
|
||||
|
||||
- Set(集合)
|
||||
|
||||
Set(集合)是一个无序、无重复元素的集合。元素间用逗号分隔,再用大括号 {} 将所有元素括起来。当Set中无元素时要用set()表示,而不是用{}表示,因为这会和空的Dict混淆。 例如:Set1 = {1, 2, 3}。为了便于和 Dict 作区分,可以把 Set 看作是一组key的集合,只存储key,不存储value。由于key是无序且不重复的,Set中的元素也都遵从此约束。
|
||||
|
||||
在创建一个Set时,python 3 会自动对Set中的元素进行去重,确保Set中无重复记录。
|
||||
|
||||
例如用构造函数set()创建一个Set时,当我们提供的数据有重复时,Set2 = set([1, 1, 2, 2, 4, 4]),最终生成的Set2为 {1, 2, 4}。
|
||||
|
||||
```python
|
||||
>>> Set2 = set([1, 1, 2, 2, 4, 4])>>> Set2{1, 2, 4}
|
||||
```
|
||||
|
||||
Set支持基本的增加、删除操作,以Set1 = {1, 2, 3}为例:
|
||||
|
||||
| 操作 | 命令 | 结果 |
|
||||
| ---- | -------------- | ------------ |
|
||||
| 增加 | Set1.add(4) | {1, 2, 3, 4} |
|
||||
| 删除 | Set1.remove(3) | {1, 2} |
|
||||
|
||||
通过in来判断元素是否在Set中,存在返回True,不存在返回False。
|
||||
|
||||
```python
|
||||
>>> Set1 = set([1, 2, 3])>>> 1 in Set1True>>> 4 in Set1False
|
||||
```
|
||||
|
||||
Set作为集合,支持典型的集合运算。以Set1 = {1, 2, 3}、Set2 = {1, 2, 4}为例:
|
||||
|
||||
| 操作 | 命令 | 结果 |
|
||||
| -------- | ------------------------------- | --------------- |
|
||||
| 交集 | Set1 & Set2 | {1 , 2} |
|
||||
| 并集 | Set1 \| Set2 | {1 , 2 , 3 , 4} |
|
||||
| 差集 | Set1 - Set2 | {3} |
|
||||
| 对称差集 | Set1 ^ Set2 | {3 , 4} |
|
||||
| 交集 | Set1.intersection(Set2) | {1 , 2} |
|
||||
| 并集 | Set1.union(Set2) | {1 , 2 , 3 , 4} |
|
||||
| 差集 | Set1.difference(Set2) | {3} |
|
||||
| 对称差集 | Set1.symmetric_difference(Set2) | {3 , 4} |
|
||||
|
||||
### 1.2.4 常用操作符
|
||||
|
||||
除了多种数据类型和对应的处理方法,Python还提供了多种操作符,使开发者们能够方便简洁的组合运用从而实现程序业务逻辑。
|
||||
|
||||
- 注释
|
||||
|
||||
注释是开发者们编写程序和阅读程序时非常有帮助的功能。大大提高了代码的可读性。在Python 3 中使用井号 # 来标识注释,一段注释需要以井号开头,井号所在行后边所有的内容都被视作注释的内容。所以注释既可以发生在一行代码的开头,也可以发生在中间。
|
||||
|
||||
```
|
||||
>>> #注释内容1>>> print('文本内容1')文本内容1>>> str1 = '文本内容1'#注释内容1>>> print(str1)文本内容1
|
||||
```
|
||||
|
||||
通常单行注释使用井号。当需要注释的内容涉及多行时,通常采用三个单引号 ''' 或三个双引号 """来标记注释内容 ,即在注释的多行内容首位添加该符号。这种情况一般被叫做块注释或批量注释。这样的注释还常常被称为文档字符串。
|
||||
|
||||
- 转义
|
||||
|
||||
在Python中使用反斜杠\转义特定字符,倘若不想转义,只需在字符串前加r或R。就可以在字符串中显示原始的反斜线符号。
|
||||
|
||||
```python
|
||||
>>> print( '转义\n字符' )转义字符>>> print( r'转义\n字符' )转义\n字符>>> print( R'转义\n字符' )转义\n字符
|
||||
```
|
||||
|
||||
以下为一些比较常用的转义字符情况。
|
||||
|
||||
| 转义字符 | 说明 |
|
||||
| -------- | ---------------------------- |
|
||||
| \\\ | 生成一个反斜杠 \ |
|
||||
| \\' | 生成一个单引号 ' |
|
||||
| \\" | 生成一个双引号 " |
|
||||
| \t | tab |
|
||||
| \r | 回车 |
|
||||
| \n | 换行 |
|
||||
| \000 | NULL,空值,\0和\000效果一致 |
|
||||
|
||||
### 1.2.5 流程控制语句
|
||||
|
||||
python通过条件判断和循环的方式实现程序代码执行流程的控制。常用的条件判断语句为if,常用的循环语句为for和while。
|
||||
|
||||
- 条件判断
|
||||
|
||||
Python提供的完整if判断语句,由if、elif、else三部分组成。 其中elif子句相当于其他编程语言常出现的else if。完整的if条件判断语句编写样式如下所示:
|
||||
|
||||
```python
|
||||
if condition1: statement1 elif condition2: statement2 else: statement3
|
||||
```
|
||||
|
||||
if 子句后边的 condition1 是该子句的判断条件。
|
||||
|
||||
当 condition1 为 True 时,执行 if 子句对应的代码块 statement1。
|
||||
|
||||
当 condition1 为 False 时,跳过 if 子句,执行 elif 子句。
|
||||
|
||||
elif 子句后边的 condition2 是该子句的判断条件。
|
||||
|
||||
当 condition2 为 True 时,执行 elif 子句对应的代码块 statement2。
|
||||
|
||||
当 condition2 为 False 时,跳过 elif 子句,执行 else 子句对应的代码块 statement3。
|
||||
|
||||
if判断语句的if、elif、else三个子句在使用上要遵守一定的原则:
|
||||
|
||||
if 子句必须出现且为第一个判断子句。
|
||||
|
||||
elif 子句可以不使用或使用多次。
|
||||
|
||||
else子句可以不使用,如果使用必须作为最后一个判断子句。
|
||||
|
||||
```python
|
||||
#多个elifif condition1: statement1 elif condition2: statement2 elif condition3: statement3 else: statement4 #缺失elifif condition1: statement1 else: statement2 #缺失elseif condition1: statement1 elif condition2: statement2 #仅有ifif condition1: statement1
|
||||
```
|
||||
|
||||
由于 Python 3 中并没有提供 switch、case 类的条件判断语句,所以开发者们可以通过在 if 子句后边追加多个 elif 子句的方法实现类似效果。
|
||||
|
||||
```python
|
||||
score = 60if score < 60: print('不及格')elif score < 85: print('还不错')elif score <= 100: print('优秀')else: print('数据异常')
|
||||
```
|
||||
|
||||
- while 循环
|
||||
|
||||
while 语句是构建一个循环的最简单方法,只需要定义一个条件,当条件满足时,就执行 while 子句中的内容。当条件不满足时循环终止,并执行 else 子句中的内容。
|
||||
|
||||
完整的 while 循环语句编写样式如下所示:
|
||||
|
||||
```python
|
||||
while condition: statement1else: statement2
|
||||
```
|
||||
|
||||
while 后边的 condition 是循环的判断条件。
|
||||
|
||||
当 condition 为 True 时,执行 while 子句的代码块 statement1。
|
||||
|
||||
当 condition 为 False 时,跳出 while 循环。执行 else 子句的代码块 statement2。
|
||||
|
||||
由于else子句可缺省,在没有else子句的情况下,当condition条件不满足时,直接跳出while循环。
|
||||
|
||||
```python
|
||||
while condition: statement
|
||||
```
|
||||
|
||||
以下代码通过 while 循环来计算 5 个 10 相加之和:
|
||||
|
||||
```python
|
||||
num = 1res = 0while num <= 5: res += 10 num += 1else: print(res)
|
||||
```
|
||||
|
||||
- for 循环
|
||||
|
||||
for 语句在构建一个循环时,需要指定用于循环的序列,通常是一个List或者Tuple。
|
||||
|
||||
完整的 for 循环语句编写样式如下所示:
|
||||
|
||||
```python
|
||||
for i in seq: statement1else: statement2
|
||||
```
|
||||
|
||||
变量 i 遍历序列 seq 中的每一个元素,并在遍历的过程中不断重复执行代码块 statement1。
|
||||
|
||||
当 i 遍历完 seq 中的所有元素后,for 循环结束。
|
||||
|
||||
当循环无法启动时,执行 else 子句对应的代码块 statement2。
|
||||
|
||||
以下代码通过 for 循环来计算 5 个 10 相加之和:
|
||||
|
||||
```python
|
||||
res = 0for i in [10, 10, 10, 10, 10]: res = res + ielse: print(res)
|
||||
```
|
||||
|
||||
由于else子句可缺省,在没有else子句的情况下,for循环可简化成以下形式:
|
||||
|
||||
```python
|
||||
for i in seq: statement1
|
||||
```
|
||||
|
||||
开发者们在编写程序时遇到的情况往往是多种多样的。为了让循环更灵活,python 提供了循环控制命令。
|
||||
|
||||
| 命令 | 说明 |
|
||||
| -------- | ---------------------------------------------------------- |
|
||||
| break | 终止循环。 用break结束循环后,循环对应的else 子句不会执行 |
|
||||
| continue | 跳过本次循环剩余操作,直接进入下次循环 |
|
||||
| pass | 站位语句,没有实际意义 |
|
||||
|
||||
### 1.2.6 了解Python的编码风格
|
||||
|
||||
不同的开发语言都有各自不同特点,这也导致各自的开发规范不尽相同。
|
||||
|
||||
Python的语法比较简单,和其他语言相比定义了相对较少的关键字,并采用了缩进的方式来控制代码块之间的逻辑关系,这也是Python最大特色。所以代码看起来显得结构清晰,简单易懂。
|
||||
|
||||
- 缩进
|
||||
|
||||
使用缩进来划分语句块,缩进的空格数是可变的,相同缩进程度的的语句隶属于同一个语句块。摒弃了其他开发语言常用的大括号 {},代码看起来更简洁。一般建议使用4个空格缩进,避免使用制表符。
|
||||
|
||||
单行代码不宜过长,最好保持在几十个字符以内。需要注释时,尽量保证注释放单独的一行。
|
||||
|
||||
- 变量命名
|
||||
|
||||
Python 规定变量的命名只能是字母、数字、下划线 _ 的组合。且变量名的首位只能字母或者下划线。这里所说的字母,并不局限于26个英文字母,还可以使用中文字符、日文字符等。当然,这建议大家给变量命名是尽量在字母这一块只是用26个英文字母。例如:num_1、\_num1 是合法变量名,而 1num_ 就是非法的。
|
||||
|
||||
需要注意的是,系统定义的关键字不能当变量名使用。另外 Python 是大小写敏感的,这就意味着同一个字母大小写不同时,代表着不同的意义。例如:Num 和 num 表示不同的变量。
|
||||
|
||||
```python
|
||||
>>> Num = 1>>> num = 2>>> print(Num)1>>> print(num)2
|
||||
```
|
||||
|
||||
Python简化了变量的定义过程。变量和变量的数据类型不需要事先声明,在给变量赋值时,既定义了变量名,有定义了变量的数据类型。即代表你给变量赋值了什么类型的数据,变量就是什么数据类型。
|
||||
|
||||
- 关键字
|
||||
|
||||
Python 3 定义的关键字并不多,且关键字本身也很简洁。我们可以通过 keyword 模块的 kwlist 查看到所有的关键词。
|
||||
|
||||
```python
|
||||
>>> import keyword>>> keyword.kwlist['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
|
||||
```
|
||||
|
||||
## 1.3 输入输出(IO)
|
||||
|
||||
在软件开发过程中,必然要涉及到输入输出。Python在这方面的设计也非常简便。input() 方法用于支持输入标准数据。支持标准输出显示输出的常用方法为print()。
|
||||
|
||||
input() 能够接受一个标准输入数据,可以简单的理解为从标准输入中获取数据。比如下面例子中 input() 方法获取到键盘输入的 good morning,并将其转成字符串。
|
||||
|
||||
```python
|
||||
>>> input()good morning'good morning'
|
||||
```
|
||||
|
||||
print() 方法将接收到的 'good morning' 显示输出。
|
||||
|
||||
```python
|
||||
>>> str = 'good morning'>>> print(str)good morning
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 1.3.1 文件的打开与读取
|
||||
|
||||
读写文件也是常见的IO操作,Python 3 内置了相关的方法。通过内置方法 open() 打开文件,返回对应的 file 对象,通过 file 对象的提供的方法读取并解析文件内容。
|
||||
|
||||
```python
|
||||
>>> open( file, mode='r')
|
||||
```
|
||||
|
||||
调用open() 方法比较常见的形式如上所示:
|
||||
|
||||
file:打开的文件
|
||||
|
||||
mode:打开文件的模式,默认模式为只读(r),可缺省。
|
||||
|
||||
mode的模式也有很多,常见的几种模式如下:
|
||||
|
||||
| 方法 | 说明 |
|
||||
| ---- | ------------------------------------------------------------ |
|
||||
| r | 打开一个文件用于只读,文件指针将会放在文件的开头。 |
|
||||
| r+ | 打开一个文件用于读写,文件指针将会放在文件的开头。 |
|
||||
| w | 打开一个文件用于只写,如果该文件已存在,则将其覆盖。如果该文件不存在,创建新文件。 |
|
||||
| w+ | 打开一个文件用于读写。如果该文件已存在,则将其覆盖。如果该文件不存在,创建新文件。 |
|
||||
| a | 打开一个文件用于只写。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件。 |
|
||||
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件。 |
|
||||
|
||||
open() 方法打开一个文件后,返回file对象,需要操作file对象从而获取文件的内容。
|
||||
|
||||
file 对象的属性如下:
|
||||
|
||||
| 属性 | 说明 |
|
||||
| ----------- | --------------------------- |
|
||||
| file.closed | 文件关闭为True,否则为False |
|
||||
| file.mode | 文件访问模式 |
|
||||
| file.name | 文件名称 |
|
||||
|
||||
file 对象的主要方法如下:
|
||||
|
||||
| 方法 | 说明 |
|
||||
| ------------------------ | ------------------------------------------------------------ |
|
||||
| file.close() | 关闭文件 |
|
||||
| file.truncate() | 清空文件内容,必须是在可写的模式下 |
|
||||
| file.flush() | 把缓冲区内容写入文件 |
|
||||
| file.read( [size] ) | 读取文件,返回结果的数据类型为List,每个字节作为一个list元素。size参数用来说明读取的字节数,可缺省 |
|
||||
| file.readline() | 读取一行,包括每行结尾的 \n 符。返回结果的数据类型为List,每个字节作为一个list元素 |
|
||||
| file.readlines( [size] ) | 读取多行,返回结果的数据类型为List,文件的每一行作为一个list元素。 参数size读取的行数,默认读取全部行,可缺省 |
|
||||
| file.write( str ) | 把str写入文件 |
|
||||
| file.writelines( list ) | 把list中的所有元素写入文件 |
|
||||
|
||||
### 1.3.2 文件与目录操作
|
||||
|
||||
在操作中,文件都是放在某个文件夹目录下的,Python 3 内置的os模块可以让开发者们轻松地处理文件,目录,路径。
|
||||
|
||||
在介绍os模块之前我们想先来了解一下文件,目录,路径三者的关系。用公式表示就是:
|
||||
|
||||
路径 = 目录 + 文件
|
||||
|
||||
下面的介绍中我们将用path表示路径,dir表示目录,file表示文件。path = dir + file
|
||||
|
||||
os模块提供的主要方法如下:
|
||||
|
||||
| 方法 | 说明 |
|
||||
| ---------------------------------------- | -------------------------------------------- |
|
||||
| os.getcwd() | 获取当前工作目录 |
|
||||
| os.listdir( dir ) | 返回指定目录dir下的所有文件和文件夹名 |
|
||||
| os.remove(path) | 删除指定文件 |
|
||||
| os.rmdir(dir) | 删除单级目录,要求该目录下无内容 |
|
||||
| os.removedirs(dir) | 删除多级目录,要求每级目录下无内容 |
|
||||
| os.mkdir(dir) | 创建单级目录 |
|
||||
| os.makedirs(dir) | 创建多级目录,当多级文件夹都不存在,同时创建 |
|
||||
| os.rename (oldpath/file, newpath/file) | 文件或目录的移动或重命名 |
|
||||
| os.walk( dir ) | 遍历指定目录 |
|
||||
|
||||
os.sep 给出当前操作系统的路径分隔符,windows下为 \\。
|
||||
|
||||
os.linesep 给出当前操作系统的行终止符。Windows下为 \r\n。
|
||||
|
||||
下面我们通过例子详细介绍一下walk()方法:os.walk( dir )。
|
||||
|
||||
dir为指定的目录,返回值为tuple(dir, subdirs, files)。
|
||||
|
||||
dir:起始目录。类型为string。
|
||||
|
||||
subdirs:起始路径下的所有子目录。类型为list。
|
||||
|
||||
filenames:起始路径下的所有文件。类型为list。
|
||||
|
||||
假设存在以下目录结构:
|
||||
|
||||
E:\data
|
||||
|
||||
part1\
|
||||
|
||||
4.txt
|
||||
|
||||
5.txt
|
||||
|
||||
part2\
|
||||
|
||||
8.txt
|
||||
|
||||
9.txt
|
||||
|
||||
1.txt
|
||||
|
||||
则os.walk()方法的结果如下:
|
||||
|
||||
```python
|
||||
>>> import os>>> for i in os.walk('E:\\data'): print(i) # 输出结果为:('E:\\data', ['part1', 'part2'], ['1.txt'])('E:\\data\\part1', [], ['4.txt', '5.txt'])('E:\\data\\part2', [], ['8.txt', '9.txt'])
|
||||
```
|
||||
|
||||
显示目录下所有路径:
|
||||
|
||||
```python
|
||||
>>> import os>>> for root, dirs, files in os.walk("E:\\data"): for dir in dirs: print(os.path.join(root, dir)) for file in files: print(os.path.join(root, file))# 输出结果为: E:\data\part1E:\data\part2E:\data\1.txtE:\data\part1\4.txtE:\data\part1\5.txtE:\data\part2\8.txtE:\data\part2\9.txt
|
||||
```
|
||||
|
||||
os.path 模块提供针对文件更喜欢的方法:
|
||||
|
||||
| 方法 | 说明 |
|
||||
| ----------------------------- | ------------------------------------------------------------ |
|
||||
| os.path.isdir(dir) | 判断是否是目录 |
|
||||
| os.path.isfile(path) | 判断是否是文件 |
|
||||
| os.path.exists(path/dir) | 判断路径/目录 |
|
||||
| os.path.dirname(path) | 返回目录 |
|
||||
| os.path.basename(path) | 返回文件名 <br />os.path.basename("E:\\Data\\1.txt") 返回值:'1.txt' |
|
||||
| os.path.join( dir, file/dir ) | 拼接目录与文件名/目录<br />os.path.join("E:\\Data","1.txt") 返回值:'E:\\Data\\1.txt' os.path.join("E:\\Data","1") 返回值:'E:\\Data\\1' |
|
||||
| os.path.getsize(path) | 返回文件大小 |
|
||||
| os.path.split(path) | 返回一个路径的目录和文件构成的tuple os.path.split("E:\\Data\\1.txt") 返回值:('E:\\Data', '1.txt') |
|
||||
| os.path.splitext(path) | 返回一个路径的目录文件名和文件后缀名构成的tuple os.path.splitext("E:\\Data\\1.txt") 返回值:('E:\\Data\\1', '.txt') |
|
||||
|
||||
|
||||
|
||||
### 1.3.3 JSON格式处理
|
||||
|
||||
JSON (JavaScript Object Notation) 是目前软件开发中非常受欢迎的一种数据交换格式。Python3 中提供了 json 模块来对 JSON 格式的数据进行编解码,主要用到两个方法,dumps()方法实现编码。loads()方法实现解码。
|
||||
|
||||
```python
|
||||
>>> import json>>> j = { 1:'attr1', 2:'attr2', 3:'attr3' }>>> json.dumps(j)'{"1": "attr1", "2": "attr2", "3": "attr3"}'
|
||||
```
|
||||
|
||||
通过dump()方法将输入 j 转换成 JSON 格式:'{"1": "attr1", "2": "attr2", "3": "attr3"}'。需要注意的是,标准JSON格式的字符串必须使用双引号",而不能使用单引号 '。
|
||||
|
||||
## 1.4 函数
|
||||
|
||||
在软件开发过程中,编写函数上开发者们经常要遇到的工作。针对不同业务开发了诸多函数后,接下来的开发工作中可以很方便的重复使用。函数帮助程序实现模块化,便于代码的复用,提高了代码的可读性。函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
|
||||
|
||||
我们前面用到的print(),open()等方法,就是非常典型的函数,他们都是由Python预先准备好的,被称为内建函数。
|
||||
|
||||
### 1.4.1 函数的基本定义
|
||||
|
||||
定义函数使用 def 关键字,一般格式如下:
|
||||
|
||||
```python
|
||||
def func( p1, p2 ...): codes return res1, res2 ...
|
||||
```
|
||||
|
||||
函数以关键字def开头,后边的func表示函数名称,圆括号 () 中的 p1、p2 表示函数的输入参数,简称入参。函数的入参必须放在圆括号内,且支持多个入参。
|
||||
|
||||
圆括号 () 后必须跟冒号 : ,冒号 :表示后边的内容都是函数内容,通常称为函数体。本例中,第二行开始表示函数的具体内容,需要相对第一行进行缩进。
|
||||
|
||||
关键词return后跟res1、res2,表示函数的返回值为res1、res2,定义函数时可以没有关键字return,此时函数返回值为 None。return是一个函数结束的标志,即执行完return整个函数就会结束运行。res可以是任意数据类型,且return的返回值没有个数限制,当返回多个值时,返回值之间用逗号分隔。
|
||||
|
||||
### 1.4.2 函数调用
|
||||
|
||||
想要在程序中调用某个函数,只需要知道该函数的名称和参数限制既可。
|
||||
|
||||
```python
|
||||
>>> def func(i): print(i) # 调用函数func>>> func('Hello')Hello
|
||||
```
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
```
|
||||
# def func():# print('1111')# print('222')# print('333')(4)函数调用阶段执行代码4、函数定义的三种形式定义函数时的参数就是函数体接收外部传值的一种媒介,其实就是一个变量名(1)、无参函数#在函数定义阶段括号内没有参数注意:定义无参,意味着调用时也无需传入参数应用:如果函数体的代码逻辑不需要依赖外部传入的值,必须定义无参函数# def func():# print('hello world')# func()(2)、有参函数#在函数定义阶段括号内有参数,称为有参函数注意:定义时有参,意味着调用时也必须传入参数应用:如果函数体代码逻辑需要依赖外部传入的值,必须定义成有参函数# def sum2(x,y):# # x=10# # y=20# res=x+y# print(res)## sum2(10,20)# sum2(30,40)(3)空函数# def func():# pass
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 1.4.3 递归函数
|
||||
|
||||
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
|
||||
|
||||
举个例子,我们来计算阶乘`n! = 1 x 2 x 3 x ... x n`,用函数`fact(n)`表示,可以看出:
|
||||
|
||||
fact(n)=n!=1\times2\times3\times\cdot\cdot\cdot\times(n-1)\times n=(n-1)!\times n=fact(n-1)\times n*f**a**c**t*(*n*)=*n*!=1×2×3×⋅⋅⋅×(*n*−1)×*n*=(*n*−1)!×*n*=*f**a**c**t*(*n*−1)×*n*
|
||||
|
||||
所以,`fact(n)`可以表示为`n x fact(n-1)`,只有n=1时需要特殊处理。
|
||||
|
||||
于是,`fact(n)`用递归的方式写出来就是:
|
||||
|
||||
```
|
||||
def fact(n): if n==1: return 1 return n * fact(n - 1)
|
||||
```
|
||||
|
||||
上面就是一个递归函数。可以试试:
|
||||
|
||||
```
|
||||
>>> fact(1)1>>> fact(5)120>>> fact(100)93326215443944152681699238856266700490715968264381621468592963895217599993229915608941463976156518286253697920827223758251185210916864000000000000000000000000
|
||||
```
|
||||
|
||||
如果我们计算`fact(5)`,可以根据函数定义看到计算过程如下:
|
||||
|
||||
```ascii
|
||||
===> fact(5)===> 5 * fact(4)===> 5 * (4 * fact(3))===> 5 * (4 * (3 * fact(2)))===> 5 * (4 * (3 * (2 * fact(1))))===> 5 * (4 * (3 * (2 * 1)))===> 5 * (4 * (3 * 2))===> 5 * (4 * 6)===> 5 * 24===> 120
|
||||
```
|
||||
|
||||
递归函数的优点是定义简单,逻辑清晰。理论上,所有的递归函数都可以写成循环的方式,但循环的逻辑不如递归清晰。
|
||||
|
||||
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。可以试试`fact(1000)`:
|
||||
|
||||
```
|
||||
>>> fact(1000)Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 4, in fact ... File "<stdin>", line 4, in factRuntimeError: maximum recursion depth exceeded in comparison
|
||||
```
|
||||
|
||||
解决递归调用栈溢出的方法是通过**尾递归**优化,事实上尾递归和循环的效果是一样的,所以,把循环看成是一种特殊的尾递归函数也是可以的。
|
||||
|
||||
尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
|
||||
|
||||
上面的`fact(n)`函数由于`return n * fact(n - 1)`引入了乘法表达式,所以就不是尾递归了。要改成尾递归方式,需要多一点代码,主要是要把每一步的乘积传入到递归函数中:
|
||||
|
||||
### 1.4.4 匿名函数
|
||||
|
||||
### Lambda 表达式
|
||||
|
||||
可以用 [`lambda`](https://docs.python.org/zh-cn/3.8/reference/expressions.html#lambda) 关键字来创建一个小的匿名函数。这个函数返回两个参数的和: `lambda a, b: a+b` 。Lambda函数可以在需要函数对象的任何地方使用。它们在语法上限于单个表达式。从语义上来说,它们只是正常函数定义的语法糖。与嵌套函数定义一样,lambda函数可以引用所包含域的变量:
|
||||
|
||||
\>>>
|
||||
|
||||
```
|
||||
>>> def make_incrementor(n):... return lambda x: x + n...>>> f = make_incrementor(42)>>> f(0)42>>> f(1)43
|
||||
```
|
||||
|
||||
上面的例子使用一个lambda表达式来返回一个函数。另一个用法是传递一个小函数作为参数:
|
||||
|
||||
\>>>
|
||||
|
||||
```
|
||||
>>> pairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]>>> pairs.sort(key=lambda pair: pair[1])>>> pairs[(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]
|
||||
```
|
||||
|
||||
python 使用 lambda 来创建匿名函数。
|
||||
|
||||
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
|
||||
|
||||
- lambda 只是一个表达式,函数体比 def 简单很多。
|
||||
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
|
||||
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
|
||||
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
|
||||
|
||||
|
||||
|
||||
lambda 函数的语法只包含一个语句,如下:
|
||||
|
||||
```
|
||||
lambda [arg1 [,arg2,.....argn]]:expression
|
||||
```
|
||||
|
||||
如下实例:
|
||||
|
||||
\#!/usr/bin/python3 # 可写函数说明 sum = lambda arg1, arg2: arg1 + arg2 # 调用sum函数 print ("相加后的值为 : ", sum( 10, 20 )) print ("相加后的值为 : ", sum( 20, 20 ))
|
||||
|
||||
以上实例输出结果:
|
||||
|
||||
```
|
||||
相加后的值为 : 30相加后的值为 : 40
|
||||
```
|
||||
|
||||
### 1.4.5 装饰器
|
||||
|
||||
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
|
||||
|
||||
```
|
||||
>>> def now():... print('2015-3-25')...>>> f = now>>> f()2015-3-25
|
||||
```
|
||||
|
||||
函数对象有一个`__name__`属性,可以拿到函数的名字:
|
||||
|
||||
```
|
||||
>>> now.__name__'now'>>> f.__name__'now'
|
||||
```
|
||||
|
||||
现在,假设我们要增强`now()`函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改`now()`函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
|
||||
|
||||
本质上,decorator就是一个返回函数的高阶函数。所以,我们要定义一个能打印日志的decorator,可以定义如下:
|
||||
|
||||
```
|
||||
def log(func): def wrapper(*args, **kw): print('call %s():' % func.__name__) return func(*args, **kw) return wrapper
|
||||
```
|
||||
|
||||
观察上面的`log`,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助Python的@语法,把decorator置于函数的定义处:
|
||||
|
||||
```
|
||||
@logdef now(): print('2015-3-25')
|
||||
```
|
||||
|
||||
调用`now()`函数,不仅会运行`now()`函数本身,还会在运行`now()`函数前打印一行日志:
|
||||
|
||||
```
|
||||
>>> now()call now():2015-3-25
|
||||
```
|
||||
|
||||
把`@log`放到`now()`函数的定义处,相当于执行了语句:
|
||||
|
||||
```
|
||||
now = log(now)
|
||||
```
|
||||
|
||||
由于`log()`是一个decorator,返回一个函数,所以,原来的`now()`函数仍然存在,只是现在同名的`now`变量指向了新的函数,于是调用`now()`将执行新函数,即在`log()`函数中返回的`wrapper()`函数。
|
||||
|
||||
`wrapper()`函数的参数定义是`(*args, **kw)`,因此,`wrapper()`函数可以接受任意参数的调用。在`wrapper()`函数内,首先打印日志,再紧接着调用原始函数。
|
||||
|
||||
如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数,写出来会更复杂。比如,要自定义log的文本:
|
||||
|
||||
```
|
||||
def log(text): def decorator(func): def wrapper(*args, **kw): print('%s %s():' % (text, func.__name__)) return func(*args, **kw) return wrapper return decorator
|
||||
```
|
||||
|
||||
这个3层嵌套的decorator用法如下:
|
||||
|
||||
```
|
||||
@log('execute')def now(): print('2015-3-25')
|
||||
```
|
||||
|
||||
执行结果如下:
|
||||
|
||||
```
|
||||
>>> now()execute now():2015-3-25
|
||||
```
|
||||
|
||||
和两层嵌套的decorator相比,3层嵌套的效果是这样的:
|
||||
|
||||
```
|
||||
>>> now = log('execute')(now)
|
||||
```
|
||||
|
||||
我们来剖析上面的语句,首先执行`log('execute')`,返回的是`decorator`函数,再调用返回的函数,参数是`now`函数,返回值最终是`wrapper`函数。
|
||||
|
||||
以上两种decorator的定义都没有问题,但还差最后一步。因为我们讲了函数也是对象,它有`__name__`等属性,但你去看经过decorator装饰之后的函数,它们的`__name__`已经从原来的`'now'`变成了`'wrapper'`:
|
||||
|
||||
|
||||
|
||||
----
|
||||
|
||||
需要注意的是,python中并没有定义“常量”这样的数据类型。
|
||||
|
||||
- 在运算符前后和逗号后使用空格,但不能直接在括号内使用: `a = f(1, 2) + g(3, 4)`。
|
||||
- 以一致的规则为你的类和函数命名;按照惯例应使用 `UpperCamelCase` 来命名类,而以 `lowercase_with_underscores` 来命名函数和方法。 始终应使用 `self` 来命名第一个方法参数 (有关类和方法的更多信息请参阅 [初探类](https://docs.python.org/zh-cn/3.8/tutorial/classes.html#tut-firstclasses))。
|
||||
- 如果你的代码旨在用于国际环境,请不要使用花哨的编码。Python 默认的 UTF-8 或者纯 ASCII 在任何情况下都能有最好的表现。
|
||||
- 同样,哪怕只有很小的可能,遇到说不同语言的人阅读或维护代码,也不要在标识符中使用非ASCII字符。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
开发者们 编写程序
|
||||
|
||||
Python ,Python 3
|
||||
450
language/Python区块链/Python语法基础.md
Normal file
450
language/Python区块链/Python语法基础.md
Normal file
@@ -0,0 +1,450 @@
|
||||
# 第1章 Python语法基础
|
||||
|
||||
Python 是一种面向对象的、解释型的、通用的、开源的脚本编程语言。
|
||||
|
||||
Python是由荷兰数学和计算机科学研究学会的Guido van Rossum 于1990 年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言,随着版本的不断更新和语言新功能的添加,逐渐被用于独立的、大型项目的开发。
|
||||
|
||||
目前主流的Python版本已经到3.x,从2020年开始,Python官方将不再对Python2进行维护,官方建议开发者尽快迁移到Python3上。需要注意的是,虽然两个版本多数语法比较类似,Python3并不兼容Python2,也就是说此前使用Python2编写的程序并不能保证可以在Python3环境下正常运行。对于开发者来说,入门学习自然是要紧跟官方建议,本书的语法内容也是基于Python3编写而成的。
|
||||
## 1.1 初识Python
|
||||
|
||||
Python因为其语法简洁、优雅、易于理解,一直被认为是最“简单”的开发语言。从入门角度来说,这样的评价不无道理,对于有其他开发语言经验的学习者来说,Python的基础语法也许只需要短短几天就能比较熟悉了,但是如果想要真正地掌握Python这门语言,仅仅是熟悉语法基础还远远不够。Python最大的特点是拥有海量的第三方类库,作为开发者,如何用最小的代价开发出所需要的功能,则需要对Python的常用类库有所了解。从这个方面来讲,Python的学习,熟悉语法后不断去使用、练习,才能在日后的使用中得心应手。
|
||||
### 1.1.1 为什么要学习Python
|
||||
|
||||
<font color=red>人生苦短,我用Python!这是入坑Python之后听到的第一句名言,Python的优势在于丰富的第三方库,尤其是人工智能方向。事实证明,当一门语言和某个火热的行业绑定时,它必将前途无量!</font>正如10年前Android的崛起带动Java的再次起飞,最近几年人工智能技术的火热使得Python炙手可热了起来。
|
||||
|
||||
下图1-1是截至2021年9月的TIOBE编程语言排行榜。
|
||||
|
||||

|
||||
|
||||
<center>图1-1-1 TIOBE编程语言排行榜</center>
|
||||
|
||||
从排行榜上可以看出,时至今日,Python已经力压Java成为第二受欢迎的编程语言,距离排名第一的C语言也只有0.16%的微弱差距,从趋势来看,Python登顶最受欢迎的编程语言榜首似乎只是时间问题。
|
||||
|
||||
正是因为有了如此繁荣的生态环境,无数的开发者也为Python提供了庞大的第三方开源类库供用户调用。为了实现一个功能,在其他语言中往往需要几十数百行的代码,在Python中也许就只是一句类库的调用就足够了。Python以其优雅和易于理解的语法著称,就连《Thinking in C++》和《Thinking in Java》的作者Bruce Eckel也曾感叹:“Life is short,you need Python(人生苦短,你该用Python)”。作为一门脚本语言,只要在拥有运行Python的环境,也许是你正在使用的PC上,也许是在公司的服务器上,也许就只是在一台Open Wrt路由器上,Python程序都可以无需编译就直接运行。
|
||||
|
||||
可能很多读者会问,Python是不是更适合搞人工智能,不适合区块链行业呢?其实不然。正如前面提到的,人生苦短,你需要使用Python,在区块链领域也没有问题。区块链系统就像是数据库一样,会为大多数开发者提供各种语言的SDK,作为这么受欢迎的语言,任何一个区块链平台都不会放弃Python的市场。就拿以太坊来说,它的节点客户端就有Go语言、Java、C++、Python等语言的不同实现版本。以太坊创始人维塔利克·布特林正在努力开发vyperlang,它是一款类似Python的智能合约开发语言。由此可见,Python可以和区块链很好的结合,Python+区块链绝对是强强组合。
|
||||
|
||||
### 1.1.2 Python开发环境搭建
|
||||
|
||||
Python官网(https://www.python.org/) 已经为各个主流系统提供了安装包文件,只需要按照自己的系统版本下载对应的安装包即可。
|
||||
|
||||
<center>图1-1-2 官网Python下载</center>
|
||||
|
||||
在Python官网主页的Downloads下拉框中,会根据你当前正在使用的系统,在右侧提供最新版的Python版本的下载链接,如果读者需要下载指定版本或指定平台的Python安装包,可以在左侧的列表中根据实际情况自行选择。
|
||||
|
||||
本书以Windows系统为例,点击下载Python3.10.0后双击安装包,开始安装。
|
||||
|
||||
<center>图1-1-3 开始安装Python</center>
|
||||
|
||||
Install Now会自动安装到默认目录中,Customize installation可以自定义Python的安装目录,修改是否下载附加组件等内容。
|
||||
|
||||
安装完成后,点击键盘的<kbd>Win</kbd>+<kbd>R</kbd>,输入“cmd”进入Windows的命令行模式。
|
||||
输入:
|
||||
```python
|
||||
python --version
|
||||
```
|
||||
如果命令行返回
|
||||
|
||||
```python
|
||||
Python 3.10.0
|
||||
```
|
||||
说明你的Python环境已经安装完成了。
|
||||
|
||||
### 1.1.3 选择一个适合的IDE
|
||||
|
||||
工欲善其事,必先利其器。想要快速开发Python程序,使用一款适合的IDE是非常关键的。下面,我们介绍可以用于开发Python代码的IDE。
|
||||
|
||||
* 文本编辑器
|
||||
|
||||
文本编辑器其实不能称之为IDE,作为初学者,最开始学习Python基础语法时,使用类记事本的编辑器也未尝不是一个好的选择。当然这里我们还是不建议你选择windows自带的记事本程序,因为该程序在最终保存时,会默认在文本的开头部分添加一个(UTF-8 BOM)的头部标识,这会导致程序在运行时出现一些莫名其妙的问题。
|
||||
|
||||
就轻量级的文本编辑器而言,笔者推荐使用Notepad++或Editra等第三方文本编辑器。
|
||||
|
||||
* IDLE
|
||||
|
||||
IDLE是Python默认提供的集成开发环境,当我们安装好Python后,也会默认安装上IDLE。IDLE具备基本的IDE功能,具有自动缩进、语法高亮、关键词自动完成等功能。在这些功能的帮助下,可以有效地提高开发者阅读和编写代码的效率。但是一般情况下不建议直接使用IDLE作为日常开发Python的IDE工具,相较于下面介绍的几种IDE来说,IDLE还是略显简易。
|
||||
|
||||
* PyCharm
|
||||
|
||||
使用文本编辑器写一些简单的小程序当然是没有问题的,但是到了大型项目中,往往需要同时管理数百个文件,各个文件之间还存在相互引用关系,这个时候使用智能IDE几乎就成了必然的选择。如果此前你有过Java、JS等其他语言的编程经验,一定听说过Jetbrains公司的大名,PyCharm就是他们为Python开发者提供的一款IDE工具,这款工具提供代码编写、调试、测试工具的一整套工具链。
|
||||
|
||||
你可以通过这个地址下载Pycharm (https://www.jetbrains.com/pycharm/download/),Jetbrains提供了Professional(专业版)和Community(社区版)两种版本,相比于免费的社区版,专业版内置了连接Sql数据库,支持在线编写代码,编辑Html、JS等强大功能,但是对于大多数Python开发者而言,社区版的功能已经足以满足绝大多数的开发场景。
|
||||
|
||||
|
||||
* VS Code
|
||||
|
||||
VS Code是微软推出的一款跨平台、支持插件扩展的智能IDE工具,它会在安装后自动检测系统中是否已经安装过Python的开发环境,智能提示你安装所需的插件。同时支持语法高亮、自动补全,相比较文本编辑器而言功能较为完善,又比PyCharm更轻量级。
|
||||
|
||||
本书中接下来的Python代码都将在PyCharm中完成,这里笔者也建议读者朋友们可以使用PyCharm来作为开发Python的首选IDE。
|
||||
|
||||
### 1.1.4 写下你的第一个Python程序
|
||||
所有学习编程的开发者都是从"Hello World"开始自己的编程之旅,学习Python时也不例外。
|
||||
|
||||
打开你的IDE,在任意的英文目录中新建一个HelloWorld.py文件
|
||||
|
||||

|
||||
<center>图1-1-4 创建HelloWorld.py</center>
|
||||
|
||||
打开这个文件后,在文件内写下
|
||||
|
||||
```python
|
||||
print("Hello World!")
|
||||
```
|
||||
|
||||
随后命令行进入这个文件所在目录,使用
|
||||
```python
|
||||
python HelloWorld.py
|
||||
```
|
||||
|
||||
运行这个程序,你将会在控制台中看到打印出来的“Hello World!”语句。
|
||||
|
||||

|
||||
<center>图1-1-5 运行HelloWorld.py</center>
|
||||
|
||||
只是简单打印一句语句看起来还不够“酷”?没问题,可以让我们的程序更加“智能”一点。
|
||||
|
||||
```python
|
||||
name = input("请输入您的姓名:") # 获取用户输入内容
|
||||
print("Hello", name)
|
||||
```
|
||||
这样在运行程序后,界面会打印出一行文字:
|
||||
在输入您的姓名后,程序会自动跟您打招呼。
|
||||

|
||||
<center>图1-1-6 再次运行HelloWorld.py</center>
|
||||
|
||||
## 1.5 异常处理
|
||||
|
||||
Python中一般会出现两类错误问题,第一种是在编写时不符合语言规范的语法错误,另外一种则是所谓的程序异常。
|
||||
|
||||
语法错误如下:
|
||||
```python
|
||||
# 1.5.1 语法错误,后一个单引号是中文字符,这也是很多初学编程的开发者经常犯的错误
|
||||
name = 'name’
|
||||
```
|
||||
使用Pycharm编写代码时,当出现语法错误时一般会通过下划红线提示出来。如下图1-1-7所示:
|
||||
|
||||
|
||||
<center>图1-1-7 语法错误</center>
|
||||
|
||||
这样的错误一般无需运行程序,在编写代码时IDE就能检测出来,运行程序也会有对应的错误提示。
|
||||
|
||||
另外一种情况则要稍微复杂一些,这也是我们本节要重点介绍的内容。代码语法是正确的,但是到了运行时,却会因为用户输入内容有误、程序获取的数据不符合预期等原因,导致程序无法获得期望的输入数据,或者不能按照期望的流程执行。
|
||||
|
||||
例如下面这段代码,程序期望获取的是一个数字,计算这个数字的一半是多少。
|
||||
|
||||
```python
|
||||
# 1.5.2 期望获取一个数字,并计算它的一半是多少
|
||||
num = "50"
|
||||
print(num/2)
|
||||
```
|
||||
|
||||
但是num的值却是一个字符串,这样在运行时就会出现下图这样的异常。
|
||||
|
||||

|
||||
<center>图1-1-8 程序异常</center>
|
||||
|
||||
可以看到,编译器会提示我们“unsupported operand type(s) for /: 'str' and 'int'”,不支持对str(字符型)和int(整型)做除法操作。
|
||||
|
||||
这样的异常情况在大型项目中会经常出现,程序运行过程中出现了预期之外的情况出现,这又会导致后续的流程无法正常运行。因此提前预判这样的情况以保证程序正常运行,这就是我们需要去处理的所谓异常。
|
||||
|
||||
对于程序异常,Python提供了完善的异常检查机制,可以将异常情况“扼杀在摇篮里”。
|
||||
### 1.5.1 错误处理思想
|
||||
|
||||
Python中已经预设了多种异常情况,具体如下表所示:
|
||||
|
||||
|异常名称| 描述 |
|
||||
|:----|:---------|
|
||||
| BaseException| 所有异常的基类 |
|
||||
| SystemExit | 解释器请求退出 |
|
||||
| KeyboardInterrupt | 用户中断执行(通常是输入^C)|
|
||||
| Exception | 常规错误的基类|
|
||||
| StopIteration | 迭代器没有更多的值|
|
||||
| GeneratorExit | 生成器(generator)发生异常来通知退出|
|
||||
| StandardError | 所有的内建标准异常的基类|
|
||||
| ArithmeticError |所有数值计算错误的基类|
|
||||
| FloatingPointError |浮点计算错误|
|
||||
| OverflowError| 数值运算超出最大限制|
|
||||
| ZeroDivisionError |除(或取模)零 (所有数据类型)|
|
||||
|AssertionError| 断言语句失败|
|
||||
|AttributeError |对象没有这个属性|
|
||||
|EOFError |没有内建输入,到达EOF 标记|
|
||||
|EnvironmentError|操作系统错误的基类|
|
||||
|IOError|输入/输出操作失败|
|
||||
|OSError|操作系统错误|
|
||||
|WindowsError|系统调用失败|
|
||||
|ImportError|导入模块/对象失败|
|
||||
|LookupError|无效数据查询的基类|
|
||||
|IndexError|序列中没有此索引(index)|
|
||||
|KeyError|映射中没有这个键|
|
||||
|MemoryError|内存溢出错误(对于Python 解释器不是致命的)|
|
||||
|NameError|未声明/初始化对象 (没有属性)|
|
||||
|UnboundLocalError|访问未初始化的本地变量|
|
||||
|ReferenceError|弱引用(Weak reference)试图访问已经垃圾回收了的对象|
|
||||
|RuntimeError|一般的运行时错误|
|
||||
|NotImplementedError|尚未实现的方法|
|
||||
|SyntaxError|Python 语法错误|
|
||||
|IndentationError|缩进错误|
|
||||
|TabError|Tab 和空格混用|
|
||||
|SystemError|一般的解释器系统错误|
|
||||
|TypeError|对类型无效的操作|
|
||||
|ValueError|传入无效的参数|
|
||||
|UnicodeError|Unicode 相关的错误|
|
||||
|UnicodeDecodeError|Unicode 解码时的错误|
|
||||
|UnicodeEncodeError|Unicode 编码时错误|
|
||||
|UnicodeTranslateError|Unicode 转换时错误|
|
||||
|Warning|警告的基类|
|
||||
|DeprecationWarning|关于被弃用的特征的警告|
|
||||
|FutureWarning|关于构造将来语义会有改变的警告|
|
||||
|OverflowWarning|旧的关于自动提升为长整型(long)的警告|
|
||||
|PendingDeprecationWarning| 关于特性将会被废弃的警告|
|
||||
|RuntimeWarning|可疑的运行时行为(runtime behavior)的警告|
|
||||
|SyntaxWarning|可疑的语法的警告|
|
||||
|UserWarning|用户代码生成的警告|
|
||||
|
||||
<center>图1-1-9 Python异常分类列表</center>
|
||||
|
||||
Python处理异常主要通过预设在代码中的try-except语句来捕获可能发生的异常,如果存在不在上表异常类型的情况,Python同样支持自定义异常类型,通过raise将该异常类型抛出,由调用方通过try-except来捕获这个异常。
|
||||
### 1.5.2 try语句使用
|
||||
|
||||
Python的异常捕获语句和Java语法极为相似,try代码块内是检测异常的区域,在该区域内存在except中定义的异常,会直接跳转到对应的except代码块内。
|
||||
|
||||
```python
|
||||
# 1.5.3 try-except的使用
|
||||
try:
|
||||
num = "50"
|
||||
print(num/2)
|
||||
except TypeError as e:
|
||||
print("捕获到异常:", e)
|
||||
```
|
||||
|
||||
这样就可以捕获到前面我们提到的异常。
|
||||
|
||||
如果在一段程序中,无论是否出现异常,都期望程序能执行一些特定的操作,可以通过try-except-finally来实现,finally代码段的内容,无论是否出现异常情况都会执行。
|
||||
|
||||
```python
|
||||
# 1.5.4 try-except-finally的使用
|
||||
try:
|
||||
num = "50"
|
||||
print(num/2)
|
||||
except TypeError as e:
|
||||
print("捕获到异常:", e)
|
||||
finally:
|
||||
print("无论是否发生异常,这里都会执行")
|
||||
```
|
||||
|
||||
这种情况多数用在一些对数据资源的访问上,例如打开一个文本文件,无论是否在读取过程中出错,都需要最终关闭这个文件以释放资源,这个操作就可以在finally中来完成。
|
||||
|
||||
如果想要在一个except中同时捕获多个预定义异常,有两种方式来处理
|
||||
* 多个并行的except
|
||||
|
||||
```python
|
||||
# 1.5.5 多个except的使用
|
||||
try:
|
||||
num = "50"
|
||||
print(num / 2)
|
||||
except TypeError as e:
|
||||
print("捕获到的字符串与数字数学运算的异常:", e)
|
||||
except ZeroDivisionError as e:
|
||||
print("捕获到的除数为0的异常", e)
|
||||
finally:
|
||||
print("无论是否发生异常,这里都会执行")
|
||||
```
|
||||
* 一个except中包含多个类型的异常
|
||||
|
||||
```python
|
||||
# 1.5.6 多个except的使用
|
||||
try:
|
||||
num = 50
|
||||
print(num / 0)
|
||||
except (TypeError, ZeroDivisionError) as e:
|
||||
print("捕获到的的异常:", e)
|
||||
finally:
|
||||
print("无论是否发生异常,这里都会执行")
|
||||
```
|
||||
|
||||
如果不确定try代码块中的异常类型,也可以不指定异常类型,或者捕获所有异常的父类BaseException,这样捕捉到的任何异常都会在except代码块中处理。
|
||||
|
||||
* 不指定异常类型
|
||||
```python
|
||||
# 1.5.7 捕获所有异常
|
||||
try:
|
||||
num = 50
|
||||
print(num / 0)
|
||||
except:
|
||||
print("捕获到的任意异常")
|
||||
finally:
|
||||
print("无论是否发生异常,这里都会执行")
|
||||
```
|
||||
|
||||
* 捕获异常的基类
|
||||
|
||||
默认情况下所有异常都是继承自BaseException,所以捕获BaseException就可以匹配到所有的异常类型。
|
||||
|
||||
```python
|
||||
# 1.5.8 捕获所有异常
|
||||
try:
|
||||
num = 50
|
||||
print(num / 0)
|
||||
except BaseException as e:
|
||||
print("捕获到的任意异常:", e)
|
||||
finally:
|
||||
print("无论是否发生异常,这里都会执行")
|
||||
```
|
||||
|
||||
可以看到,相比于不指定异常类型,捕获BaseException的优点在于,可以获取到导致程序异常的具体信息,我们也可以在except中对异常做相应的判断和针对性的处理。
|
||||
|
||||
* 使用raise向外抛出异常
|
||||
|
||||
使用raise可以不对异常做处理,而是将该异常抛给上一层,也就是调用方,由调用方来处理这个异常。这样的处理多是在方法定义中,可以让外部的调用方有更灵活的异常处理方式。
|
||||
|
||||
```python
|
||||
def addNum():
|
||||
num1Str = input("请输入第1个数字:")
|
||||
if(not num1Str.isdigit()):
|
||||
raise Exception("您输入的不是数字!", num1Str)
|
||||
num2Str = input("请输入第2个数字:")
|
||||
if(not num2Str.isdigit()):
|
||||
raise Exception("您输入的不是数字!", num2Str)
|
||||
|
||||
floatNum1 = float(num1Str)
|
||||
floatNum2 = float(num2Str)
|
||||
return floatNum1 + floatNum2
|
||||
|
||||
try:
|
||||
addNum()
|
||||
except BaseException as e:
|
||||
print(e)
|
||||
```
|
||||
|
||||
上面的示例中,我们定义了一个加法函数,提示用户输入两个数字,函数会自动计算两个数字的和。如果用户输入的内容不是数字,那么这个加法操作流程必然无法执行,因此我们需要提前判断用户输入的内容。
|
||||
|
||||
在Python中,通过input获取到的输入内容都是string字符串,我们通过字符串内置的isdigit()方法来判断其是否为数字类型,如果不是,函数会通过raise向外抛出一个Exception异常,并提示用户“您输入的不是数字!”,这样在调用该函数时,通过try-except就可以实时判断用户输入的内容是否符合函数的要求。
|
||||

|
||||
### 1.5.3 断言语句
|
||||
|
||||
断言一般用于单元测试中,用于判断一个表达式,以及这个表达式为False时触发的异常。在Python中,断言的语法为
|
||||
|
||||
> assert expression [, arguments]
|
||||
|
||||
当assert中的条件为假时,会抛出第二个参数定义的异常信息。
|
||||
|
||||
```python
|
||||
num1Str = "m"
|
||||
assert(num1Str.isdigit(), "num1Str不是数字!")
|
||||
```
|
||||
|
||||
等价于
|
||||
|
||||
```python
|
||||
num1Str = "m"
|
||||
if(num1Str.isdigit()):
|
||||
pass
|
||||
else:
|
||||
raise AssertionError("num1Str不是数字!")
|
||||
```
|
||||
|
||||
需要注意的是,断言只是作为调试程序的一种手段,一般是用来发现Python脚本中的异常。断言所检测的异常,在执行Python代码时是可以被忽略的。因此当我们通过断言定位并修改问题后,断言内容随后也就可以去掉。
|
||||
|
||||
## 1.6 面向对象编程
|
||||
|
||||
几乎所有的高级语言都是面向对象的,相比于面向过程,面向对象的编程方式更适合人类的思维模式。在中大型项目中,面向对象的编程风格也可以极大地节约代码量。
|
||||
|
||||
Python提供了对面向对象编程的支持,有着完善的类、对象以及方法的定义和使用规范。
|
||||
### 1.6.1 面向对象的编程思想
|
||||
|
||||
面向对象最重要的三个特点即为封装、继承、多态。
|
||||
|
||||
封装性可以保证在编程时可以将同一类事物的属性和方法封装到一个类中, 通过方法来修改和执行业务, 有利于后期的修改和维护。继承可以实现方法的多态性和代码的可重用性。多态则是为了解决现实生活中的多样性问题, 相同的指令对应不同的子对象,会有该对象特有的执行方式。
|
||||
|
||||
举一个简单的例子,假设有一个学生类,学生又都有年龄、年级的属性以及学习这样的方法。在面向对象编程中,我们就可以定义一个学生的父类,其中包含了上述的属性和方法,这里就体现了面向对象的封装性,将同一类事物封装在一个类中。学生中又分为小学生、中学生和大学生,可以根据这些分类创建不同的子类,这些子类也就继承了父类中的属性和方法,这里就体现了面向对象的继承性。不同的学生学习这个方法最终实现会有所不同,例如小学生学习的是小学知识,中学生学习的自然是中学知识,因此仅就“学习”这一个相同的方法,不同的子类可能会有不同的处理,这里就体现出了面向对象的多态性。
|
||||
### 1.6.2 Python的面向对象特色
|
||||
|
||||
Python中定义一个类
|
||||
```python
|
||||
class Student(object):
|
||||
def __init__(self, name, age, grade):
|
||||
self.name = name
|
||||
self.age = age
|
||||
self.grade = grade
|
||||
|
||||
def study(self):
|
||||
print(self.name+"在学习基础知识")
|
||||
|
||||
|
||||
baseStudent = Student("学生0", 10, 3)
|
||||
print("baseStudent的name:", baseStudent.name)
|
||||
print("baseStudent的age:", baseStudent.age)
|
||||
print("baseStudent的grade:", baseStudent.grade)
|
||||
baseStudent.study()
|
||||
```
|
||||
|
||||
class是Python中用来定义类的标准字符,Student(object)说明当前定义的类继承自object类,如同Java中的类都是继承自Object类一样,Python中的类也都是继承自object类。Student类中的__init__方法是构造函数的定义,是这个类的对象被初始化时默认会调用的方法。
|
||||
|
||||
像__init__这样以前后双下划线的方式命名的方法名,是Python中的“魔术方法(magic method)”,对Python系统来说,这将确保不会与用户自定义的名称冲突。
|
||||
|
||||
Python中定义对象直接命名对象名即可,不能像Java那样,在对象名前显式指定类名。等号后的Student("学生0", 10, 3)就是对Student对象的实例化,这行代码会自动调用类构造函数,需要注意的是,在Python类定义的函数,第一个参数都是self,这个参数代表当前正在使用的对象,我们可以通过它获取到当前对象内的属性。
|
||||
|
||||
接下来我们定义Student的两个子类:PrimaryStudent和JuniorStudent,它们会各自实现自己的study方法
|
||||
```python
|
||||
class PrimaryStudent(Student):
|
||||
def study(self):
|
||||
print(self.name+"在学习小学知识")
|
||||
|
||||
|
||||
class JuniorStudent(Student):
|
||||
def study(self):
|
||||
print(self.name+"在学习初中知识")
|
||||
|
||||
|
||||
primaryStudent = PrimaryStudent("小学生", 7, 1)
|
||||
print("primaryStudent的name:", primaryStudent.name)
|
||||
print("primaryStudent的age:", primaryStudent.age)
|
||||
print("primaryStudent的grade:", primaryStudent.grade)
|
||||
primaryStudent.study()
|
||||
|
||||
juniorStudent = JuniorStudent("中学生", 13, 7)
|
||||
print("juniorStudent的name:", juniorStudent.name)
|
||||
print("juniorStudent的age:", juniorStudent.age)
|
||||
print("juniorStudent的grade:", juniorStudent.grade)
|
||||
juniorStudent.study()
|
||||
```
|
||||
上面的示例可以看到,PrimaryStudent和JuniorStudent虽然都没有在类中定义自己的age、grade以及name,但是因为在定义类时,继承了Student,它们也就继承了父类Student定义的这些属性。而在两个子类中各自重写了父类的study方法后,也会自动调用子类中的方法。
|
||||
|
||||
> 类属性和方法的访问限制
|
||||
|
||||
Python中对类属性和方法的访问限制,主要是通过名称来控制的。当名称包含两个下划线“__”,则说明这是一个私有变量或私有方法。上面的例子中,当我们把name改为__name,在外部就无法访问到这个属性了。
|
||||
|
||||
```python
|
||||
class Student(object):
|
||||
def __init__(self, name, age, grade):
|
||||
self.__name = name
|
||||
self.age = age
|
||||
self.grade = grade
|
||||
|
||||
def study(self):
|
||||
print(self.__name+"在学习基础知识")
|
||||
|
||||
student = Student("小学生", 7, 1)
|
||||
print("student的name:", student.__name)
|
||||
```
|
||||
|
||||
执行上面的程序,会提示Student没有__name这个属性,因为__name对外部是不可见的。
|
||||
|
||||
```
|
||||
AttributeError: 'Student' object has no attribute '__name'
|
||||
```
|
||||
|
||||
在Python中,如果属性名或方法名以单个下划线开头,则说明这是一个受保护的属性或方法,它表示“虽然我可以在外部被访问,但是最好不要这样做”。
|
||||
|
||||
## 疑难解答
|
||||
### 1. 为什么建议使用python 3.x 而不是python 2.x?
|
||||
### 2. 为什么都说Python相比于其它语言更简单?
|
||||
事实上想要真正精通Python一点也不简单,只是Python的入门基础知识比较简单,学习曲线较为平滑,而这些基础知识已经可以应付生活工作中的80%以上的场景。不像有些语言那样,很多初学者往往都是倒在入门的门槛上,根本都没有机会能够流畅地学完所有的基础语法。
|
||||
|
||||
另外Python因为具备海量的第三方库,很多即使是刚刚入门的同学也能迅速结合这些第三方库,“黏合”出一个看上去比较复杂的程序,就像造一辆汽车,C语言往往需要从如何挖矿开始,Java需要从如何拧螺丝钉开始,而Python则是直接提供了轮子、方向盘、底盘,你只需要按照自己的想法将这些组件搭建起来,就可以“造”出一辆汽车,这其中哪一个难度更低就显而易见了。
|
||||
|
||||
简单来讲,Python可以在学习中给予学习者更多的正反馈,这种正反馈也就让学习者有了Python相较其他语言更“简单”的感觉。
|
||||
## 实训:如何用Python轻松处理excel
|
||||

|
||||
|
||||

|
||||
1
language/Python区块链/README.md
Normal file
1
language/Python区块链/README.md
Normal file
@@ -0,0 +1 @@
|
||||
这是一个Python基础教程的文档
|
||||
5
language/Python区块链/_sidebar.md
Normal file
5
language/Python区块链/_sidebar.md
Normal file
@@ -0,0 +1,5 @@
|
||||
* [第1篇 Python基础篇](./Python基础篇.md "Python基础篇")
|
||||
* [第1章 Python语法基础](./Python语法基础.md "Python语法基础")
|
||||
* [第1章 Python语法基础-辛](./Python语法基础-辛.md "Python语法基础-辛")
|
||||
* [第2章 Python的语法特色](./Python的语法特色.md "Python的语法特色")
|
||||
* [第3章 Python与数据库](./Python与数据库.md "Python与数据库")
|
||||
24
language/Python区块链/tempCodeRunnerFile.python
Normal file
24
language/Python区块链/tempCodeRunnerFile.python
Normal file
@@ -0,0 +1,24 @@
|
||||
from typing import List
|
||||
|
||||
|
||||
def is_valid_walk(walk):
|
||||
if len(walk) != 10:
|
||||
return False
|
||||
|
||||
hasWalk = list()
|
||||
|
||||
for m in walk:
|
||||
if (m == 'n' and hasWalk.index('s')>=0):
|
||||
hasWalk.remove(hasWalk.index('s'))
|
||||
elif (m == 's' and hasWalk.index('n')>=0):
|
||||
hasWalk.remove(hasWalk.index('n'))
|
||||
elif (m == 'e' and hasWalk.index('w')>=0):
|
||||
hasWalk.remove(hasWalk.index('w'))
|
||||
elif (m == 'w' and hasWalk.index('e')>=0):
|
||||
hasWalk.remove(hasWalk.index('e'))
|
||||
else:
|
||||
hasWalk.append(m)
|
||||
|
||||
return len(hasWalk) == 0
|
||||
|
||||
print(is_valid_walk(['n','s','n','s','n','s','n','s','n','s']))
|
||||
BIN
language/Python区块链/反馈:第1章-修改-小小.docx
Normal file
BIN
language/Python区块链/反馈:第1章-修改-小小.docx
Normal file
Binary file not shown.
BIN
language/Python区块链/第1章-修改-小小-太能喵-2021-11-11.docx
Normal file
BIN
language/Python区块链/第1章-修改-小小-太能喵-2021-11-11.docx
Normal file
Binary file not shown.
BIN
language/Python区块链/第3章/第3章 Python与数据库-修改-220308.docx
Normal file
BIN
language/Python区块链/第3章/第3章 Python与数据库-修改-220308.docx
Normal file
Binary file not shown.
BIN
language/Python区块链/第3章/第3章 Python与数据库-修改-220411.docx
Normal file
BIN
language/Python区块链/第3章/第3章 Python与数据库-修改-220411.docx
Normal file
Binary file not shown.
Reference in New Issue
Block a user